install.packages("keras")
reticulate::install_miniconda()
keras::install_keras(method="conda", python_version="3.11")34 Neural Networks in R (with Keras)
34.1 Introduction
Working with neural networks in R can be a bit challenging. For one, there are many packages available that can train ANNs, see Table 34.1 for some examples. The packages vary greatly in capabilities and syntax.
Several frameworks for ANNs and deep learning exist. TensorFlow, Microsoft CNTK, PyTorch, and Theano are among the most important ones.
R packages for neural network analysis.
| Package | Notes |
|---|---|
nnet |
Feed-forward neural networks with a single hidden layer, and for multinomial log-linear models |
neuralnet |
Training of neural networks using backpropagation |
tensorflow |
Interface to TensorFlow, a free and open-source software library for machine learning and artificial intelligence |
darch |
Deep architectures and Restricted Boltzmann Machines |
deepnet |
Deep learning toolkit |
deepr |
Streamlines training, tuning, and predicting for deep learning based on darch and deepnet |
rnn |
Recurrent Neural Networks (RNN) |
torch |
Tensors and neural networks with GPU acceleration; similar to Pytorch |
keras |
Interface to the Python deep learning library Keras |
kerasR |
Interface to the Python deep learning library Keras |
Keras has emerged as an important API (Application Programming Interface) for deep learning. It provides a consistent interface on top of JAX, TensorFlow, or PyTorch. While TensorFlow is very powerful, the learning curve can be steep and you tend to write a lot of code. On the other hand, you have complete control over the types of models you build and train with TensorFlow. That makes Keras so relevant: you can tap into the capabilities of TensorFlow with a simpler API.
The drawback of using Keras and other deep learning frameworks in R is that they are written in Python. Tools from the modern machine learning toolbox tend to be written in Python. The keras package in R is not an implementation of Keras in R, it is an R-based API that calls into the Keras Python code. And that code calls into Tensorflow, or whatever deep learning framework Keras is running on.
To use keras in R, you thus need to manage a Python distribution, manage Python packages, and deal with the idiosyncrasies of function interfaces between programming languages. For example, you will have to deal with Python error messages bubbling up to the R session. Fortunately, some of the headaches of running Python from R are mitigated by the reticulate package which provides the R interface to Python.
Tip
The KerasR package is not the same as the keras package in R. Both packages provide an API for Keras and the API of KerasR is closer to the Python syntax. That makes switching between R and Python for deep learning easier. However, the keras package supports piping of operations similar to the dplyr package. I find working with keras simple because neural networks can be build by piping layer definitions. After all, that is how neural networks work: the output of one layer is input to the next layer.
We will be using the keras package in R. It uses the TensorFlow framework under the cover by default.
34.2 Running Keras in R
Installation
As mentioned earlier, running keras requires a Python distribution. In addition, you need to install the Keras and TensorFlow Python libraries. The preferred Python installation in this case is conda-based. Good instructions for installing TensorFlow, Keras, and the Python runtime at once—depending on whether you have a prior conda installation—can be found here.
In the situation without prior conda installation, these commands will install everything you need (do this once in your environment):
Then, in an R session that runs keras do the following:
library(keras)
reticulate::use_condaenv(condaenv = "r-tensorflow")The "r-tensorflow" conda environment was installed during the previous step.
Keras Basics
Training a neural network with keras involves three steps:
Defining the network
Setting up the optimization
Fitting the model
Not until the third step does the algorithm get in contact with actual data. However, we need to know some things about the data in order to define the network in step 1: the dimensions of the input and output.
Defining the network
The most convenient way of specifying a multi layer neural network is by adding layers sequentially, from the input layer to the output layer. These starts with a call to keras_model_sequential(). Suppose we want to predict a continuous response (regression application) based on inputs \(x_1, \cdots, x_{20}\) with one hidden layer and dropout regularization.
The following statements define the model sequentially:
firstANN <- keras_model_sequential() %>%
layer_dense(units =50,
activation ="relu",
input_shape=19
) %>%
layer_dropout(rate=0.4) %>%
layer_dense(units=1,
name ="Output") layer_dense() adds a fully connected layer to the networks, the units= option specifies the number of neurons in the layer. The input_shape= option is specified only for the first layer in the network. In summary, the hidden layer receives 20 inputs and has 50 output units (neurons) and ReLU activation. The output from the hidden layer is passed on (piped) to a dropout layer with a dropout rate of \(\phi = 0.4\). The result of the dropout layer is passed on to another fully connected layer with a single neuron. This is the output layer of the network. In other words, the last layer in the sequence is automatically the output layer. Since we are in a regression context to predict a numeric target variable, there is only one output unit in the final layer. If this was a classification problem with \(5\) categories, the last layer would have 5 units.
You can assign a name to each layer with the name= option, this makes it easier to identify the layers in output. If you do not specify a name, Keras will assign a name that combines a description of the layer type with a numerical index (not always). The numeric indices can be confusing because they depend on counters internal to the Python code. Assigning an explicit name is recommended practice.
The activation= option specifies the activation function \(\sigma()\) for the hidden layers and the output function \(g()\) for the output layer. The default is the identity (“linear”) activation, \(\sigma(x) = x\). This default is appropriate for the output layer in a regression application. For the hidden layer we choose the ReLU activation.
To see the list of activation functions supported by keras (Keras), type the following at the console prompt:
?keras::actiThe basic neural network is now defined and we can find out how many parameters it entails.
summary(firstANN)Model: "sequential"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
dense (Dense) (None, 50) 1000
dropout (Dropout) (None, 50) 0
Output (Dense) (None, 1) 51
================================================================================
Total params: 1051 (4.11 KB)
Trainable params: 1051 (4.11 KB)
Non-trainable params: 0 (0.00 Byte)
________________________________________________________________________________With 19 inputs and 50 neurons, the first layer has 50 x 20 = 1,000 parameters (19 slopes and an intercept for each output neuron). The dropout layer does not add any parameters to the estimation, it chooses output neurons of the previous layer at random and sets their activation to zero. The 50 neurons (some with activation set randomly to zero) are the input to the final layer, adding fifty weights (slopes) and one bias (intercept). The total number of parameters of this neural network is 1,051.
Setting up the optimization
The second step in training a model in Keras is to specify the particulars of the optimization with the keras::compile() function (which actually calls keras::compile.keras.engine.training.Model). Typical specifications include the loss functions, the type of optimization algorithm, and the metrics evaluated by the model during training.
The following function call uses the RMSProp algorithm with mean-squared error loss function to estimate the parameters of the network. During training, the mean absolute error is also monitored in addition to the mean squared error.
firstANN %>% compile(loss="mse", # see keras$losses$
optimizer=optimizer_rmsprop(), # see keras$optimizers$
metrics=list("mean_absolute_error") # see keras$metrics$
)Depending on your environment, not all optimization algorithms are supported.
Fitting the model
The last step in training the network is to connect the defined and compiled model with training—and possibly test—data.
For this example we use the Hitters data from the ISLR2 package. This is a data set with 322 observations of major league baseball players from the 1986 and 1987 seasons. The following code removes observations with missing values from the data frame, defines a vector of ids for the test data (1/3 of the observations) and computes a scaled and centered model matrix using all 20 input variables.
library(ISLR2)
Gitters <- na.omit(Hitters)
n <- nrow(Gitters)
tensorflow::set_random_seed(13)
ntest <- trunc(n / 3)
testid <- sample(1:n, ntest)
x <- scale(model.matrix(Salary ~ ., data = Gitters))
x <- x[,-1] #Remove intercept term
y <- Gitters$SalaryNote that the model contains several factors (League, Division, NewLeague) whose levels are encoded as binary variables in the model matrix. One could exclude those from scaling and centering as they already are in the proper range. In a regression model you would not want to scale these variables to preserve the interpretation of their coefficients. In a neural network interpretation of the model coefficients is not important and we include all columns of the model matrix in the scaling operation.
The following code fits the model to the training data (-testid) using 20 epochs and a minibatch size of 32. That means the gradient is computed based on 32 randomly chosen observations in each step of the stochastic gradient descent algorithm. Since there are 176 training observations it takes \(176/32=5.5\) SGD steps to process all \(n\) observations. This is known as an epoch and is akin to the concept of an iteration in numerical optimization: a full pass through the data. The fundamental difference between an epoch and an iteration lies in the fact that updates of the parameters occur after each gradient computation. In a full iteration, there is one update after the pass through the entire data. In SGD with minibatch, there are multiple updates of the parameters, one for each minibatch.
Running 200 epochs with a batch size of 32 and a training set size of 176 results in 200 * 5.5 = 1,100 gradient evaluations.
The validation_data= option lists the test data for the training. The objective function and metrics specified in the compile command earlier are computed at each epoch for the training and the test data if the latter is specified. If you do not have a validation data set, you can specify validation_split= and request that a fraction of the training data is held back for validation.
history <- firstANN %>%
fit(x[-testid, ],
y[-testid ],
epochs=200,
batch_size=32,
validation_data=list(x[testid, ], y[testid])
)Epoch 1/200
6/6 - 0s - loss: 457467.2812 - mean_absolute_error: 534.4042 - val_loss: 556154.3750 - val_mean_absolute_error: 540.1494 - 133ms/epoch - 22ms/step
Epoch 2/200
6/6 - 0s - loss: 456974.4688 - mean_absolute_error: 533.9562 - val_loss: 555786.1250 - val_mean_absolute_error: 539.8985 - 14ms/epoch - 2ms/step
Epoch 3/200
6/6 - 0s - loss: 456553.2812 - mean_absolute_error: 533.7072 - val_loss: 555450.5000 - val_mean_absolute_error: 539.6758 - 8ms/epoch - 1ms/step
Epoch 4/200
6/6 - 0s - loss: 456321.7812 - mean_absolute_error: 533.5106 - val_loss: 555140.8125 - val_mean_absolute_error: 539.4644 - 8ms/epoch - 1ms/step
Epoch 5/200
6/6 - 0s - loss: 455994.3750 - mean_absolute_error: 533.2979 - val_loss: 554823.7500 - val_mean_absolute_error: 539.2452 - 8ms/epoch - 1ms/step
Epoch 6/200
6/6 - 0s - loss: 455809.2188 - mean_absolute_error: 533.0406 - val_loss: 554539.1250 - val_mean_absolute_error: 539.0522 - 8ms/epoch - 1ms/step
Epoch 7/200
6/6 - 0s - loss: 455652.0938 - mean_absolute_error: 532.9760 - val_loss: 554246.1875 - val_mean_absolute_error: 538.8604 - 8ms/epoch - 1ms/step
Epoch 8/200
6/6 - 0s - loss: 455350.3125 - mean_absolute_error: 532.7690 - val_loss: 553958.0625 - val_mean_absolute_error: 538.6625 - 8ms/epoch - 1ms/step
Epoch 9/200
6/6 - 0s - loss: 455284.1875 - mean_absolute_error: 532.5870 - val_loss: 553685.5000 - val_mean_absolute_error: 538.4662 - 8ms/epoch - 1ms/step
Epoch 10/200
6/6 - 0s - loss: 454769.0938 - mean_absolute_error: 532.2631 - val_loss: 553364.3125 - val_mean_absolute_error: 538.2443 - 8ms/epoch - 1ms/step
Epoch 11/200
6/6 - 0s - loss: 454632.5000 - mean_absolute_error: 532.1635 - val_loss: 553071.7500 - val_mean_absolute_error: 538.0394 - 8ms/epoch - 1ms/step
Epoch 12/200
6/6 - 0s - loss: 454524.4062 - mean_absolute_error: 532.0634 - val_loss: 552767.4375 - val_mean_absolute_error: 537.8243 - 9ms/epoch - 1ms/step
Epoch 13/200
6/6 - 0s - loss: 453881.4062 - mean_absolute_error: 531.6386 - val_loss: 552414.2500 - val_mean_absolute_error: 537.5932 - 8ms/epoch - 1ms/step
Epoch 14/200
6/6 - 0s - loss: 453627.0312 - mean_absolute_error: 531.5167 - val_loss: 552085.6875 - val_mean_absolute_error: 537.3748 - 8ms/epoch - 1ms/step
Epoch 15/200
6/6 - 0s - loss: 453285.9062 - mean_absolute_error: 531.2102 - val_loss: 551760.6250 - val_mean_absolute_error: 537.1580 - 8ms/epoch - 1ms/step
Epoch 16/200
6/6 - 0s - loss: 452950.6875 - mean_absolute_error: 530.9305 - val_loss: 551411.0625 - val_mean_absolute_error: 536.9230 - 7ms/epoch - 1ms/step
Epoch 17/200
6/6 - 0s - loss: 453014.8750 - mean_absolute_error: 530.8544 - val_loss: 551049.1250 - val_mean_absolute_error: 536.6915 - 7ms/epoch - 1ms/step
Epoch 18/200
6/6 - 0s - loss: 452354.0312 - mean_absolute_error: 530.4612 - val_loss: 550694.6875 - val_mean_absolute_error: 536.4647 - 7ms/epoch - 1ms/step
Epoch 19/200
6/6 - 0s - loss: 452247.0938 - mean_absolute_error: 530.3420 - val_loss: 550319.7500 - val_mean_absolute_error: 536.2261 - 7ms/epoch - 1ms/step
Epoch 20/200
6/6 - 0s - loss: 451975.1250 - mean_absolute_error: 530.1284 - val_loss: 549953.8125 - val_mean_absolute_error: 535.9852 - 7ms/epoch - 1ms/step
Epoch 21/200
6/6 - 0s - loss: 451797.0312 - mean_absolute_error: 529.9882 - val_loss: 549584.2500 - val_mean_absolute_error: 535.7531 - 11ms/epoch - 2ms/step
Epoch 22/200
6/6 - 0s - loss: 451377.6250 - mean_absolute_error: 529.8196 - val_loss: 549173.9375 - val_mean_absolute_error: 535.4987 - 7ms/epoch - 1ms/step
Epoch 23/200
6/6 - 0s - loss: 450839.9688 - mean_absolute_error: 529.3874 - val_loss: 548780.0625 - val_mean_absolute_error: 535.2390 - 8ms/epoch - 1ms/step
Epoch 24/200
6/6 - 0s - loss: 450472.8750 - mean_absolute_error: 529.0532 - val_loss: 548348.5000 - val_mean_absolute_error: 534.9714 - 7ms/epoch - 1ms/step
Epoch 25/200
6/6 - 0s - loss: 450118.7812 - mean_absolute_error: 528.6538 - val_loss: 547942.2500 - val_mean_absolute_error: 534.7296 - 7ms/epoch - 1ms/step
Epoch 26/200
6/6 - 0s - loss: 450123.0312 - mean_absolute_error: 528.6262 - val_loss: 547517.3125 - val_mean_absolute_error: 534.4792 - 7ms/epoch - 1ms/step
Epoch 27/200
6/6 - 0s - loss: 449304.4688 - mean_absolute_error: 528.1773 - val_loss: 547033.0625 - val_mean_absolute_error: 534.1947 - 7ms/epoch - 1ms/step
Epoch 28/200
6/6 - 0s - loss: 449460.0000 - mean_absolute_error: 528.1414 - val_loss: 546585.6250 - val_mean_absolute_error: 533.9254 - 7ms/epoch - 1ms/step
Epoch 29/200
6/6 - 0s - loss: 448597.5000 - mean_absolute_error: 527.7112 - val_loss: 546119.0625 - val_mean_absolute_error: 533.6447 - 8ms/epoch - 1ms/step
Epoch 30/200
6/6 - 0s - loss: 448408.3125 - mean_absolute_error: 527.3817 - val_loss: 545607.3750 - val_mean_absolute_error: 533.3466 - 7ms/epoch - 1ms/step
Epoch 31/200
6/6 - 0s - loss: 447699.9062 - mean_absolute_error: 527.0282 - val_loss: 545098.6250 - val_mean_absolute_error: 533.0551 - 7ms/epoch - 1ms/step
Epoch 32/200
6/6 - 0s - loss: 447420.1875 - mean_absolute_error: 526.9537 - val_loss: 544591.7500 - val_mean_absolute_error: 532.7584 - 7ms/epoch - 1ms/step
Epoch 33/200
6/6 - 0s - loss: 446955.0938 - mean_absolute_error: 526.4774 - val_loss: 544092.6250 - val_mean_absolute_error: 532.4581 - 7ms/epoch - 1ms/step
Epoch 34/200
6/6 - 0s - loss: 447259.4688 - mean_absolute_error: 526.6396 - val_loss: 543598.2500 - val_mean_absolute_error: 532.1605 - 7ms/epoch - 1ms/step
Epoch 35/200
6/6 - 0s - loss: 446745.4062 - mean_absolute_error: 526.1879 - val_loss: 543096.6250 - val_mean_absolute_error: 531.8589 - 7ms/epoch - 1ms/step
Epoch 36/200
6/6 - 0s - loss: 446176.1875 - mean_absolute_error: 525.7791 - val_loss: 542549.5000 - val_mean_absolute_error: 531.5452 - 7ms/epoch - 1ms/step
Epoch 37/200
6/6 - 0s - loss: 445674.3125 - mean_absolute_error: 525.5492 - val_loss: 541973.4375 - val_mean_absolute_error: 531.2059 - 7ms/epoch - 1ms/step
Epoch 38/200
6/6 - 0s - loss: 444534.1875 - mean_absolute_error: 524.7194 - val_loss: 541358.1875 - val_mean_absolute_error: 530.8544 - 7ms/epoch - 1ms/step
Epoch 39/200
6/6 - 0s - loss: 443640.1875 - mean_absolute_error: 524.2282 - val_loss: 540771.1875 - val_mean_absolute_error: 530.5146 - 7ms/epoch - 1ms/step
Epoch 40/200
6/6 - 0s - loss: 444210.6875 - mean_absolute_error: 524.5088 - val_loss: 540187.0000 - val_mean_absolute_error: 530.1741 - 7ms/epoch - 1ms/step
Epoch 41/200
6/6 - 0s - loss: 443619.4062 - mean_absolute_error: 523.9715 - val_loss: 539556.6250 - val_mean_absolute_error: 529.8112 - 7ms/epoch - 1ms/step
Epoch 42/200
6/6 - 0s - loss: 443187.9062 - mean_absolute_error: 523.5914 - val_loss: 538983.1875 - val_mean_absolute_error: 529.4727 - 7ms/epoch - 1ms/step
Epoch 43/200
6/6 - 0s - loss: 442926.0000 - mean_absolute_error: 523.6467 - val_loss: 538349.6250 - val_mean_absolute_error: 529.1151 - 7ms/epoch - 1ms/step
Epoch 44/200
6/6 - 0s - loss: 441807.1875 - mean_absolute_error: 522.7037 - val_loss: 537681.7500 - val_mean_absolute_error: 528.7339 - 7ms/epoch - 1ms/step
Epoch 45/200
6/6 - 0s - loss: 441162.3750 - mean_absolute_error: 522.4229 - val_loss: 536989.4375 - val_mean_absolute_error: 528.3411 - 7ms/epoch - 1ms/step
Epoch 46/200
6/6 - 0s - loss: 440420.0000 - mean_absolute_error: 521.8414 - val_loss: 536311.4375 - val_mean_absolute_error: 527.9510 - 7ms/epoch - 1ms/step
Epoch 47/200
6/6 - 0s - loss: 439893.0312 - mean_absolute_error: 521.5354 - val_loss: 535670.8750 - val_mean_absolute_error: 527.5692 - 7ms/epoch - 1ms/step
Epoch 48/200
6/6 - 0s - loss: 439515.5312 - mean_absolute_error: 521.5076 - val_loss: 534959.1875 - val_mean_absolute_error: 527.1697 - 7ms/epoch - 1ms/step
Epoch 49/200
6/6 - 0s - loss: 439756.0000 - mean_absolute_error: 520.7190 - val_loss: 534240.2500 - val_mean_absolute_error: 526.7577 - 7ms/epoch - 1ms/step
Epoch 50/200
6/6 - 0s - loss: 438051.5000 - mean_absolute_error: 520.1700 - val_loss: 533476.2500 - val_mean_absolute_error: 526.3226 - 7ms/epoch - 1ms/step
Epoch 51/200
6/6 - 0s - loss: 437806.0312 - mean_absolute_error: 519.9543 - val_loss: 532709.0000 - val_mean_absolute_error: 525.8895 - 7ms/epoch - 1ms/step
Epoch 52/200
6/6 - 0s - loss: 437612.2188 - mean_absolute_error: 519.9634 - val_loss: 531932.2500 - val_mean_absolute_error: 525.4529 - 7ms/epoch - 1ms/step
Epoch 53/200
6/6 - 0s - loss: 435817.0938 - mean_absolute_error: 518.8049 - val_loss: 531097.3750 - val_mean_absolute_error: 524.9910 - 7ms/epoch - 1ms/step
Epoch 54/200
6/6 - 0s - loss: 436061.9688 - mean_absolute_error: 518.8276 - val_loss: 530390.8125 - val_mean_absolute_error: 524.5851 - 7ms/epoch - 1ms/step
Epoch 55/200
6/6 - 0s - loss: 435279.0312 - mean_absolute_error: 518.2408 - val_loss: 529562.6250 - val_mean_absolute_error: 524.1160 - 7ms/epoch - 1ms/step
Epoch 56/200
6/6 - 0s - loss: 433435.5000 - mean_absolute_error: 517.2485 - val_loss: 528706.5625 - val_mean_absolute_error: 523.6333 - 7ms/epoch - 1ms/step
Epoch 57/200
6/6 - 0s - loss: 434217.9688 - mean_absolute_error: 517.6281 - val_loss: 527877.8125 - val_mean_absolute_error: 523.1646 - 7ms/epoch - 1ms/step
Epoch 58/200
6/6 - 0s - loss: 433882.5938 - mean_absolute_error: 517.2768 - val_loss: 527030.5000 - val_mean_absolute_error: 522.6756 - 7ms/epoch - 1ms/step
Epoch 59/200
6/6 - 0s - loss: 433581.1250 - mean_absolute_error: 516.9023 - val_loss: 526156.6875 - val_mean_absolute_error: 522.1849 - 8ms/epoch - 1ms/step
Epoch 60/200
6/6 - 0s - loss: 431683.8750 - mean_absolute_error: 515.3811 - val_loss: 525316.4375 - val_mean_absolute_error: 521.6917 - 7ms/epoch - 1ms/step
Epoch 61/200
6/6 - 0s - loss: 431812.3125 - mean_absolute_error: 515.7289 - val_loss: 524435.1875 - val_mean_absolute_error: 521.1880 - 7ms/epoch - 1ms/step
Epoch 62/200
6/6 - 0s - loss: 430083.2188 - mean_absolute_error: 514.5716 - val_loss: 523465.4375 - val_mean_absolute_error: 520.6406 - 7ms/epoch - 1ms/step
Epoch 63/200
6/6 - 0s - loss: 429948.0000 - mean_absolute_error: 514.2624 - val_loss: 522526.8125 - val_mean_absolute_error: 520.1066 - 7ms/epoch - 1ms/step
Epoch 64/200
6/6 - 0s - loss: 429117.8750 - mean_absolute_error: 514.1993 - val_loss: 521585.7500 - val_mean_absolute_error: 519.5761 - 7ms/epoch - 1ms/step
Epoch 65/200
6/6 - 0s - loss: 429532.3125 - mean_absolute_error: 513.5920 - val_loss: 520647.3438 - val_mean_absolute_error: 519.0334 - 7ms/epoch - 1ms/step
Epoch 66/200
6/6 - 0s - loss: 428198.5312 - mean_absolute_error: 513.1260 - val_loss: 519642.7500 - val_mean_absolute_error: 518.4741 - 7ms/epoch - 1ms/step
Epoch 67/200
6/6 - 0s - loss: 427270.9062 - mean_absolute_error: 512.4005 - val_loss: 518576.3125 - val_mean_absolute_error: 517.8750 - 7ms/epoch - 1ms/step
Epoch 68/200
6/6 - 0s - loss: 425544.4688 - mean_absolute_error: 511.0083 - val_loss: 517654.1562 - val_mean_absolute_error: 517.3316 - 7ms/epoch - 1ms/step
Epoch 69/200
6/6 - 0s - loss: 425600.5312 - mean_absolute_error: 510.7675 - val_loss: 516635.5938 - val_mean_absolute_error: 516.7429 - 7ms/epoch - 1ms/step
Epoch 70/200
6/6 - 0s - loss: 424614.6875 - mean_absolute_error: 510.5913 - val_loss: 515634.9375 - val_mean_absolute_error: 516.1625 - 7ms/epoch - 1ms/step
Epoch 71/200
6/6 - 0s - loss: 423457.7812 - mean_absolute_error: 509.5631 - val_loss: 514578.4062 - val_mean_absolute_error: 515.5607 - 7ms/epoch - 1ms/step
Epoch 72/200
6/6 - 0s - loss: 421999.5000 - mean_absolute_error: 508.8318 - val_loss: 513490.2188 - val_mean_absolute_error: 514.9266 - 7ms/epoch - 1ms/step
Epoch 73/200
6/6 - 0s - loss: 422209.5312 - mean_absolute_error: 508.7707 - val_loss: 512385.9375 - val_mean_absolute_error: 514.3010 - 7ms/epoch - 1ms/step
Epoch 74/200
6/6 - 0s - loss: 421138.3750 - mean_absolute_error: 508.2247 - val_loss: 511308.5938 - val_mean_absolute_error: 513.6782 - 7ms/epoch - 1ms/step
Epoch 75/200
6/6 - 0s - loss: 420704.3125 - mean_absolute_error: 507.4806 - val_loss: 510169.7500 - val_mean_absolute_error: 513.0303 - 8ms/epoch - 1ms/step
Epoch 76/200
6/6 - 0s - loss: 420707.8750 - mean_absolute_error: 507.5935 - val_loss: 509099.5000 - val_mean_absolute_error: 512.3997 - 8ms/epoch - 1ms/step
Epoch 77/200
6/6 - 0s - loss: 417644.0938 - mean_absolute_error: 506.0628 - val_loss: 507966.9062 - val_mean_absolute_error: 511.7507 - 7ms/epoch - 1ms/step
Epoch 78/200
6/6 - 0s - loss: 418776.4062 - mean_absolute_error: 505.3345 - val_loss: 506790.8125 - val_mean_absolute_error: 511.0780 - 7ms/epoch - 1ms/step
Epoch 79/200
6/6 - 0s - loss: 417346.4688 - mean_absolute_error: 504.9959 - val_loss: 505623.4375 - val_mean_absolute_error: 510.3975 - 7ms/epoch - 1ms/step
Epoch 80/200
6/6 - 0s - loss: 414973.9062 - mean_absolute_error: 503.3947 - val_loss: 504401.5625 - val_mean_absolute_error: 509.6975 - 7ms/epoch - 1ms/step
Epoch 81/200
6/6 - 0s - loss: 412634.5000 - mean_absolute_error: 502.7116 - val_loss: 503147.8750 - val_mean_absolute_error: 508.9838 - 7ms/epoch - 1ms/step
Epoch 82/200
6/6 - 0s - loss: 414922.9062 - mean_absolute_error: 503.0685 - val_loss: 502036.6875 - val_mean_absolute_error: 508.2954 - 7ms/epoch - 1ms/step
Epoch 83/200
6/6 - 0s - loss: 412476.1875 - mean_absolute_error: 501.8584 - val_loss: 500884.2188 - val_mean_absolute_error: 507.6303 - 7ms/epoch - 1ms/step
Epoch 84/200
6/6 - 0s - loss: 414021.7188 - mean_absolute_error: 501.9960 - val_loss: 499745.1562 - val_mean_absolute_error: 506.9604 - 7ms/epoch - 1ms/step
Epoch 85/200
6/6 - 0s - loss: 409454.9062 - mean_absolute_error: 498.9004 - val_loss: 498503.5312 - val_mean_absolute_error: 506.2194 - 7ms/epoch - 1ms/step
Epoch 86/200
6/6 - 0s - loss: 409406.6875 - mean_absolute_error: 499.9105 - val_loss: 497199.5938 - val_mean_absolute_error: 505.4433 - 7ms/epoch - 1ms/step
Epoch 87/200
6/6 - 0s - loss: 409424.6250 - mean_absolute_error: 499.3608 - val_loss: 495950.1562 - val_mean_absolute_error: 504.7036 - 7ms/epoch - 1ms/step
Epoch 88/200
6/6 - 0s - loss: 406124.4688 - mean_absolute_error: 496.9589 - val_loss: 494586.3438 - val_mean_absolute_error: 503.9154 - 7ms/epoch - 1ms/step
Epoch 89/200
6/6 - 0s - loss: 407660.6250 - mean_absolute_error: 498.5825 - val_loss: 493265.8438 - val_mean_absolute_error: 503.1378 - 7ms/epoch - 1ms/step
Epoch 90/200
6/6 - 0s - loss: 404703.4062 - mean_absolute_error: 495.5233 - val_loss: 491944.4062 - val_mean_absolute_error: 502.3678 - 8ms/epoch - 1ms/step
Epoch 91/200
6/6 - 0s - loss: 404736.0938 - mean_absolute_error: 495.8616 - val_loss: 490553.5312 - val_mean_absolute_error: 501.5575 - 7ms/epoch - 1ms/step
Epoch 92/200
6/6 - 0s - loss: 404308.6250 - mean_absolute_error: 495.4790 - val_loss: 489303.0312 - val_mean_absolute_error: 500.7705 - 7ms/epoch - 1ms/step
Epoch 93/200
6/6 - 0s - loss: 402297.0938 - mean_absolute_error: 494.0054 - val_loss: 488026.7188 - val_mean_absolute_error: 500.0132 - 7ms/epoch - 1ms/step
Epoch 94/200
6/6 - 0s - loss: 402037.2188 - mean_absolute_error: 492.8116 - val_loss: 486717.9688 - val_mean_absolute_error: 499.2411 - 7ms/epoch - 1ms/step
Epoch 95/200
6/6 - 0s - loss: 400551.6250 - mean_absolute_error: 492.9653 - val_loss: 485310.4062 - val_mean_absolute_error: 498.3978 - 7ms/epoch - 1ms/step
Epoch 96/200
6/6 - 0s - loss: 400399.6250 - mean_absolute_error: 492.5336 - val_loss: 483943.1875 - val_mean_absolute_error: 497.5659 - 7ms/epoch - 1ms/step
Epoch 97/200
6/6 - 0s - loss: 397756.2188 - mean_absolute_error: 491.0871 - val_loss: 482511.1875 - val_mean_absolute_error: 496.7170 - 7ms/epoch - 1ms/step
Epoch 98/200
6/6 - 0s - loss: 399707.0000 - mean_absolute_error: 491.9345 - val_loss: 481140.6562 - val_mean_absolute_error: 495.8976 - 7ms/epoch - 1ms/step
Epoch 99/200
6/6 - 0s - loss: 395119.5312 - mean_absolute_error: 488.9091 - val_loss: 479693.2812 - val_mean_absolute_error: 495.0069 - 7ms/epoch - 1ms/step
Epoch 100/200
6/6 - 0s - loss: 394670.0312 - mean_absolute_error: 488.1075 - val_loss: 478228.7812 - val_mean_absolute_error: 494.1391 - 7ms/epoch - 1ms/step
Epoch 101/200
6/6 - 0s - loss: 392810.5938 - mean_absolute_error: 487.0219 - val_loss: 476750.2500 - val_mean_absolute_error: 493.2406 - 7ms/epoch - 1ms/step
Epoch 102/200
6/6 - 0s - loss: 390347.2812 - mean_absolute_error: 485.3098 - val_loss: 475143.5312 - val_mean_absolute_error: 492.3004 - 7ms/epoch - 1ms/step
Epoch 103/200
6/6 - 0s - loss: 390829.4688 - mean_absolute_error: 485.9751 - val_loss: 473707.5312 - val_mean_absolute_error: 491.3977 - 8ms/epoch - 1ms/step
Epoch 104/200
6/6 - 0s - loss: 391385.1250 - mean_absolute_error: 485.4736 - val_loss: 472339.3125 - val_mean_absolute_error: 490.5478 - 7ms/epoch - 1ms/step
Epoch 105/200
6/6 - 0s - loss: 387290.6250 - mean_absolute_error: 482.5927 - val_loss: 470851.3125 - val_mean_absolute_error: 489.6365 - 7ms/epoch - 1ms/step
Epoch 106/200
6/6 - 0s - loss: 387175.9688 - mean_absolute_error: 482.3725 - val_loss: 469322.0312 - val_mean_absolute_error: 488.7018 - 7ms/epoch - 1ms/step
Epoch 107/200
6/6 - 0s - loss: 385734.6250 - mean_absolute_error: 481.3942 - val_loss: 467905.7500 - val_mean_absolute_error: 487.7979 - 7ms/epoch - 1ms/step
Epoch 108/200
6/6 - 0s - loss: 385729.5938 - mean_absolute_error: 481.2458 - val_loss: 466418.9062 - val_mean_absolute_error: 486.8840 - 7ms/epoch - 1ms/step
Epoch 109/200
6/6 - 0s - loss: 385920.5312 - mean_absolute_error: 479.7736 - val_loss: 464928.1250 - val_mean_absolute_error: 485.9617 - 7ms/epoch - 1ms/step
Epoch 110/200
6/6 - 0s - loss: 382951.0938 - mean_absolute_error: 479.4142 - val_loss: 463380.9688 - val_mean_absolute_error: 485.0134 - 7ms/epoch - 1ms/step
Epoch 111/200
6/6 - 0s - loss: 381697.0938 - mean_absolute_error: 477.9058 - val_loss: 461771.5938 - val_mean_absolute_error: 484.0284 - 7ms/epoch - 1ms/step
Epoch 112/200
6/6 - 0s - loss: 379648.0312 - mean_absolute_error: 476.8103 - val_loss: 460247.7812 - val_mean_absolute_error: 483.0439 - 8ms/epoch - 1ms/step
Epoch 113/200
6/6 - 0s - loss: 378877.5938 - mean_absolute_error: 476.3299 - val_loss: 458659.8750 - val_mean_absolute_error: 482.0429 - 7ms/epoch - 1ms/step
Epoch 114/200
6/6 - 0s - loss: 378726.9688 - mean_absolute_error: 476.8225 - val_loss: 457105.4688 - val_mean_absolute_error: 481.0534 - 7ms/epoch - 1ms/step
Epoch 115/200
6/6 - 0s - loss: 376562.4688 - mean_absolute_error: 474.6235 - val_loss: 455464.4062 - val_mean_absolute_error: 480.0452 - 7ms/epoch - 1ms/step
Epoch 116/200
6/6 - 0s - loss: 374875.0938 - mean_absolute_error: 472.8408 - val_loss: 453810.8438 - val_mean_absolute_error: 479.0102 - 7ms/epoch - 1ms/step
Epoch 117/200
6/6 - 0s - loss: 375362.5312 - mean_absolute_error: 472.2220 - val_loss: 452200.0938 - val_mean_absolute_error: 477.9904 - 7ms/epoch - 1ms/step
Epoch 118/200
6/6 - 0s - loss: 371964.7188 - mean_absolute_error: 470.9580 - val_loss: 450603.2500 - val_mean_absolute_error: 476.9535 - 7ms/epoch - 1ms/step
Epoch 119/200
6/6 - 0s - loss: 370620.2188 - mean_absolute_error: 468.6035 - val_loss: 449062.2500 - val_mean_absolute_error: 475.9695 - 7ms/epoch - 1ms/step
Epoch 120/200
6/6 - 0s - loss: 369674.2188 - mean_absolute_error: 468.7726 - val_loss: 447433.6562 - val_mean_absolute_error: 474.9398 - 7ms/epoch - 1ms/step
Epoch 121/200
6/6 - 0s - loss: 367763.3125 - mean_absolute_error: 467.2383 - val_loss: 445675.8750 - val_mean_absolute_error: 473.8312 - 7ms/epoch - 1ms/step
Epoch 122/200
6/6 - 0s - loss: 366515.1562 - mean_absolute_error: 466.5544 - val_loss: 444023.4375 - val_mean_absolute_error: 472.7856 - 7ms/epoch - 1ms/step
Epoch 123/200
6/6 - 0s - loss: 366166.0000 - mean_absolute_error: 464.2773 - val_loss: 442364.6875 - val_mean_absolute_error: 471.7399 - 7ms/epoch - 1ms/step
Epoch 124/200
6/6 - 0s - loss: 368724.2188 - mean_absolute_error: 467.2540 - val_loss: 440706.3125 - val_mean_absolute_error: 470.6628 - 7ms/epoch - 1ms/step
Epoch 125/200
6/6 - 0s - loss: 366849.6250 - mean_absolute_error: 466.3307 - val_loss: 438992.3750 - val_mean_absolute_error: 469.5661 - 7ms/epoch - 1ms/step
Epoch 126/200
6/6 - 0s - loss: 364627.6875 - mean_absolute_error: 463.3165 - val_loss: 437412.2188 - val_mean_absolute_error: 468.5393 - 7ms/epoch - 1ms/step
Epoch 127/200
6/6 - 0s - loss: 365752.7500 - mean_absolute_error: 463.9808 - val_loss: 435675.8750 - val_mean_absolute_error: 467.4272 - 7ms/epoch - 1ms/step
Epoch 128/200
6/6 - 0s - loss: 360318.0625 - mean_absolute_error: 460.5741 - val_loss: 433991.5938 - val_mean_absolute_error: 466.2966 - 7ms/epoch - 1ms/step
Epoch 129/200
6/6 - 0s - loss: 354233.2812 - mean_absolute_error: 458.1599 - val_loss: 432150.3438 - val_mean_absolute_error: 465.0953 - 9ms/epoch - 1ms/step
Epoch 130/200
6/6 - 0s - loss: 356469.8438 - mean_absolute_error: 457.8601 - val_loss: 430437.2812 - val_mean_absolute_error: 463.9471 - 7ms/epoch - 1ms/step
Epoch 131/200
6/6 - 0s - loss: 357910.8438 - mean_absolute_error: 459.5972 - val_loss: 428886.1562 - val_mean_absolute_error: 462.9150 - 7ms/epoch - 1ms/step
Epoch 132/200
6/6 - 0s - loss: 353593.4688 - mean_absolute_error: 455.1606 - val_loss: 427098.8438 - val_mean_absolute_error: 461.7246 - 7ms/epoch - 1ms/step
Epoch 133/200
6/6 - 0s - loss: 354060.1250 - mean_absolute_error: 454.9890 - val_loss: 425289.5312 - val_mean_absolute_error: 460.5388 - 7ms/epoch - 1ms/step
Epoch 134/200
6/6 - 0s - loss: 351676.7188 - mean_absolute_error: 453.0984 - val_loss: 423548.5000 - val_mean_absolute_error: 459.3964 - 7ms/epoch - 1ms/step
Epoch 135/200
6/6 - 0s - loss: 348127.9062 - mean_absolute_error: 452.3991 - val_loss: 421700.6562 - val_mean_absolute_error: 458.1180 - 7ms/epoch - 1ms/step
Epoch 136/200
6/6 - 0s - loss: 354480.1875 - mean_absolute_error: 454.9205 - val_loss: 420074.4062 - val_mean_absolute_error: 457.0417 - 7ms/epoch - 1ms/step
Epoch 137/200
6/6 - 0s - loss: 349860.7188 - mean_absolute_error: 452.7027 - val_loss: 418162.2188 - val_mean_absolute_error: 455.7806 - 7ms/epoch - 1ms/step
Epoch 138/200
6/6 - 0s - loss: 347159.7500 - mean_absolute_error: 450.0136 - val_loss: 416355.2188 - val_mean_absolute_error: 454.5709 - 7ms/epoch - 1ms/step
Epoch 139/200
6/6 - 0s - loss: 346865.2188 - mean_absolute_error: 448.5856 - val_loss: 414577.1562 - val_mean_absolute_error: 453.3752 - 7ms/epoch - 1ms/step
Epoch 140/200
6/6 - 0s - loss: 341132.1250 - mean_absolute_error: 447.0901 - val_loss: 412650.9062 - val_mean_absolute_error: 452.1093 - 7ms/epoch - 1ms/step
Epoch 141/200
6/6 - 0s - loss: 340981.7812 - mean_absolute_error: 445.3103 - val_loss: 410813.1562 - val_mean_absolute_error: 450.8660 - 7ms/epoch - 1ms/step
Epoch 142/200
6/6 - 0s - loss: 336175.2812 - mean_absolute_error: 443.6796 - val_loss: 408917.9375 - val_mean_absolute_error: 449.6124 - 7ms/epoch - 1ms/step
Epoch 143/200
6/6 - 0s - loss: 338338.4062 - mean_absolute_error: 441.3667 - val_loss: 407068.0938 - val_mean_absolute_error: 448.3250 - 7ms/epoch - 1ms/step
Epoch 144/200
6/6 - 0s - loss: 338537.2188 - mean_absolute_error: 443.1052 - val_loss: 405374.2188 - val_mean_absolute_error: 447.1637 - 7ms/epoch - 1ms/step
Epoch 145/200
6/6 - 0s - loss: 337860.0312 - mean_absolute_error: 441.8195 - val_loss: 403584.2188 - val_mean_absolute_error: 445.9070 - 7ms/epoch - 1ms/step
Epoch 146/200
6/6 - 0s - loss: 334810.2812 - mean_absolute_error: 442.2684 - val_loss: 401770.9375 - val_mean_absolute_error: 444.6920 - 7ms/epoch - 1ms/step
Epoch 147/200
6/6 - 0s - loss: 334123.5938 - mean_absolute_error: 439.8799 - val_loss: 399964.4062 - val_mean_absolute_error: 443.4495 - 7ms/epoch - 1ms/step
Epoch 148/200
6/6 - 0s - loss: 334929.5312 - mean_absolute_error: 439.4800 - val_loss: 398063.8125 - val_mean_absolute_error: 442.1427 - 7ms/epoch - 1ms/step
Epoch 149/200
6/6 - 0s - loss: 332829.2188 - mean_absolute_error: 436.3860 - val_loss: 396186.1250 - val_mean_absolute_error: 440.8129 - 7ms/epoch - 1ms/step
Epoch 150/200
6/6 - 0s - loss: 330009.6875 - mean_absolute_error: 436.2783 - val_loss: 394224.1875 - val_mean_absolute_error: 439.5068 - 7ms/epoch - 1ms/step
Epoch 151/200
6/6 - 0s - loss: 325927.4062 - mean_absolute_error: 432.1569 - val_loss: 392460.7500 - val_mean_absolute_error: 438.2751 - 7ms/epoch - 1ms/step
Epoch 152/200
6/6 - 0s - loss: 324353.5938 - mean_absolute_error: 431.9009 - val_loss: 390477.1562 - val_mean_absolute_error: 436.9095 - 7ms/epoch - 1ms/step
Epoch 153/200
6/6 - 0s - loss: 324162.3125 - mean_absolute_error: 431.9038 - val_loss: 388628.9688 - val_mean_absolute_error: 435.6179 - 7ms/epoch - 1ms/step
Epoch 154/200
6/6 - 0s - loss: 317031.2812 - mean_absolute_error: 428.5129 - val_loss: 386655.9062 - val_mean_absolute_error: 434.2180 - 7ms/epoch - 1ms/step
Epoch 155/200
6/6 - 0s - loss: 319302.6250 - mean_absolute_error: 429.3151 - val_loss: 384816.5312 - val_mean_absolute_error: 432.9087 - 7ms/epoch - 1ms/step
Epoch 156/200
6/6 - 0s - loss: 318118.7812 - mean_absolute_error: 427.5724 - val_loss: 382931.5938 - val_mean_absolute_error: 431.5648 - 7ms/epoch - 1ms/step
Epoch 157/200
6/6 - 0s - loss: 318121.5000 - mean_absolute_error: 427.8786 - val_loss: 381115.9688 - val_mean_absolute_error: 430.2938 - 7ms/epoch - 1ms/step
Epoch 158/200
6/6 - 0s - loss: 318343.0312 - mean_absolute_error: 427.4060 - val_loss: 379250.4062 - val_mean_absolute_error: 428.9797 - 8ms/epoch - 1ms/step
Epoch 159/200
6/6 - 0s - loss: 317608.1562 - mean_absolute_error: 425.1165 - val_loss: 377344.5000 - val_mean_absolute_error: 427.7892 - 7ms/epoch - 1ms/step
Epoch 160/200
6/6 - 0s - loss: 314324.9688 - mean_absolute_error: 421.2899 - val_loss: 375498.9375 - val_mean_absolute_error: 426.6534 - 7ms/epoch - 1ms/step
Epoch 161/200
6/6 - 0s - loss: 315978.8125 - mean_absolute_error: 423.8986 - val_loss: 373580.9375 - val_mean_absolute_error: 425.4772 - 7ms/epoch - 1ms/step
Epoch 162/200
6/6 - 0s - loss: 317339.0000 - mean_absolute_error: 424.9066 - val_loss: 371891.3125 - val_mean_absolute_error: 424.3959 - 7ms/epoch - 1ms/step
Epoch 163/200
6/6 - 0s - loss: 312075.5312 - mean_absolute_error: 420.9038 - val_loss: 370045.5938 - val_mean_absolute_error: 423.2101 - 7ms/epoch - 1ms/step
Epoch 164/200
6/6 - 0s - loss: 303667.9062 - mean_absolute_error: 414.9319 - val_loss: 368031.9062 - val_mean_absolute_error: 421.9601 - 7ms/epoch - 1ms/step
Epoch 165/200
6/6 - 0s - loss: 303672.5312 - mean_absolute_error: 416.7955 - val_loss: 365975.0938 - val_mean_absolute_error: 420.6651 - 8ms/epoch - 1ms/step
Epoch 166/200
6/6 - 0s - loss: 302428.7500 - mean_absolute_error: 412.9567 - val_loss: 364015.5000 - val_mean_absolute_error: 419.4270 - 7ms/epoch - 1ms/step
Epoch 167/200
6/6 - 0s - loss: 311676.6562 - mean_absolute_error: 418.6126 - val_loss: 362224.0938 - val_mean_absolute_error: 418.2824 - 7ms/epoch - 1ms/step
Epoch 168/200
6/6 - 0s - loss: 306755.9688 - mean_absolute_error: 415.2806 - val_loss: 360323.5625 - val_mean_absolute_error: 417.0684 - 7ms/epoch - 1ms/step
Epoch 169/200
6/6 - 0s - loss: 303520.5000 - mean_absolute_error: 412.3777 - val_loss: 358466.3125 - val_mean_absolute_error: 415.8785 - 7ms/epoch - 1ms/step
Epoch 170/200
6/6 - 0s - loss: 295372.4688 - mean_absolute_error: 407.1250 - val_loss: 356348.7500 - val_mean_absolute_error: 414.5238 - 7ms/epoch - 1ms/step
Epoch 171/200
6/6 - 0s - loss: 296399.8750 - mean_absolute_error: 408.7531 - val_loss: 354423.0938 - val_mean_absolute_error: 413.2992 - 7ms/epoch - 1ms/step
Epoch 172/200
6/6 - 0s - loss: 293640.1875 - mean_absolute_error: 408.1143 - val_loss: 352407.6875 - val_mean_absolute_error: 412.0421 - 7ms/epoch - 1ms/step
Epoch 173/200
6/6 - 0s - loss: 292127.3125 - mean_absolute_error: 405.7164 - val_loss: 350396.0312 - val_mean_absolute_error: 410.7804 - 7ms/epoch - 1ms/step
Epoch 174/200
6/6 - 0s - loss: 293714.3750 - mean_absolute_error: 406.1626 - val_loss: 348474.5312 - val_mean_absolute_error: 409.5270 - 7ms/epoch - 1ms/step
Epoch 175/200
6/6 - 0s - loss: 293210.3125 - mean_absolute_error: 406.2860 - val_loss: 346629.3438 - val_mean_absolute_error: 408.3861 - 7ms/epoch - 1ms/step
Epoch 176/200
6/6 - 0s - loss: 290229.6562 - mean_absolute_error: 404.8998 - val_loss: 344824.4375 - val_mean_absolute_error: 407.2478 - 7ms/epoch - 1ms/step
Epoch 177/200
6/6 - 0s - loss: 289976.2188 - mean_absolute_error: 403.4166 - val_loss: 342881.4062 - val_mean_absolute_error: 406.0181 - 7ms/epoch - 1ms/step
Epoch 178/200
6/6 - 0s - loss: 289813.7500 - mean_absolute_error: 404.1601 - val_loss: 341107.0938 - val_mean_absolute_error: 404.8706 - 7ms/epoch - 1ms/step
Epoch 179/200
6/6 - 0s - loss: 282266.8125 - mean_absolute_error: 396.4026 - val_loss: 339136.9688 - val_mean_absolute_error: 403.6381 - 7ms/epoch - 1ms/step
Epoch 180/200
6/6 - 0s - loss: 286530.6875 - mean_absolute_error: 399.6810 - val_loss: 337304.6250 - val_mean_absolute_error: 402.4522 - 7ms/epoch - 1ms/step
Epoch 181/200
6/6 - 0s - loss: 287407.8750 - mean_absolute_error: 401.1002 - val_loss: 335303.5938 - val_mean_absolute_error: 401.1793 - 9ms/epoch - 1ms/step
Epoch 182/200
6/6 - 0s - loss: 280582.2188 - mean_absolute_error: 396.6561 - val_loss: 333375.5000 - val_mean_absolute_error: 399.9208 - 8ms/epoch - 1ms/step
Epoch 183/200
6/6 - 0s - loss: 284605.1250 - mean_absolute_error: 396.2007 - val_loss: 331454.3438 - val_mean_absolute_error: 398.6805 - 23ms/epoch - 4ms/step
Epoch 184/200
6/6 - 0s - loss: 282617.0938 - mean_absolute_error: 396.4597 - val_loss: 329484.3750 - val_mean_absolute_error: 397.3799 - 8ms/epoch - 1ms/step
Epoch 185/200
6/6 - 0s - loss: 283883.8750 - mean_absolute_error: 395.6685 - val_loss: 327526.9375 - val_mean_absolute_error: 396.1130 - 7ms/epoch - 1ms/step
Epoch 186/200
6/6 - 0s - loss: 275556.7812 - mean_absolute_error: 392.8543 - val_loss: 325666.8125 - val_mean_absolute_error: 394.8595 - 8ms/epoch - 1ms/step
Epoch 187/200
6/6 - 0s - loss: 276326.1250 - mean_absolute_error: 391.9420 - val_loss: 323848.8125 - val_mean_absolute_error: 393.6488 - 7ms/epoch - 1ms/step
Epoch 188/200
6/6 - 0s - loss: 275444.5000 - mean_absolute_error: 394.6382 - val_loss: 321915.0000 - val_mean_absolute_error: 392.3260 - 7ms/epoch - 1ms/step
Epoch 189/200
6/6 - 0s - loss: 272933.7812 - mean_absolute_error: 386.1507 - val_loss: 319944.9062 - val_mean_absolute_error: 391.0199 - 8ms/epoch - 1ms/step
Epoch 190/200
6/6 - 0s - loss: 270520.3750 - mean_absolute_error: 387.9880 - val_loss: 318009.9688 - val_mean_absolute_error: 389.7164 - 8ms/epoch - 1ms/step
Epoch 191/200
6/6 - 0s - loss: 274251.5000 - mean_absolute_error: 390.9561 - val_loss: 316193.9688 - val_mean_absolute_error: 388.5079 - 7ms/epoch - 1ms/step
Epoch 192/200
6/6 - 0s - loss: 269594.4375 - mean_absolute_error: 381.4011 - val_loss: 314352.1875 - val_mean_absolute_error: 387.2635 - 7ms/epoch - 1ms/step
Epoch 193/200
6/6 - 0s - loss: 260959.4375 - mean_absolute_error: 376.3271 - val_loss: 312464.0625 - val_mean_absolute_error: 385.9737 - 7ms/epoch - 1ms/step
Epoch 194/200
6/6 - 0s - loss: 266462.0312 - mean_absolute_error: 382.0392 - val_loss: 310521.5938 - val_mean_absolute_error: 384.6903 - 7ms/epoch - 1ms/step
Epoch 195/200
6/6 - 0s - loss: 265391.6250 - mean_absolute_error: 379.7612 - val_loss: 308764.5625 - val_mean_absolute_error: 383.5049 - 7ms/epoch - 1ms/step
Epoch 196/200
6/6 - 0s - loss: 258707.2656 - mean_absolute_error: 377.2246 - val_loss: 306686.8125 - val_mean_absolute_error: 382.1123 - 7ms/epoch - 1ms/step
Epoch 197/200
6/6 - 0s - loss: 252883.9844 - mean_absolute_error: 372.8943 - val_loss: 304874.6562 - val_mean_absolute_error: 380.8647 - 7ms/epoch - 1ms/step
Epoch 198/200
6/6 - 0s - loss: 263077.2188 - mean_absolute_error: 379.6801 - val_loss: 303130.6562 - val_mean_absolute_error: 379.6878 - 7ms/epoch - 1ms/step
Epoch 199/200
6/6 - 0s - loss: 255534.3906 - mean_absolute_error: 373.1696 - val_loss: 301218.9062 - val_mean_absolute_error: 378.5102 - 7ms/epoch - 1ms/step
Epoch 200/200
6/6 - 0s - loss: 258015.8438 - mean_absolute_error: 372.2751 - val_loss: 299418.4688 - val_mean_absolute_error: 377.3880 - 7ms/epoch - 1ms/stepKeras reports for each epoch the value of the loss metric (mean squared error) for the training and validation data and the monitored metrics (mean absolute error) for the validation data. As you can see from the lengthy output, all criteria are still decreasing after 200 epochs. It is helpful to view the epoch history graphically. If you run the code in an interactive environment (e.g., RStudio), the epoch history is displayed and updated live. You can always plot the epoch history with the plot command:
plot(history, smooth=FALSE) # see ?plot.keras_training_history for doc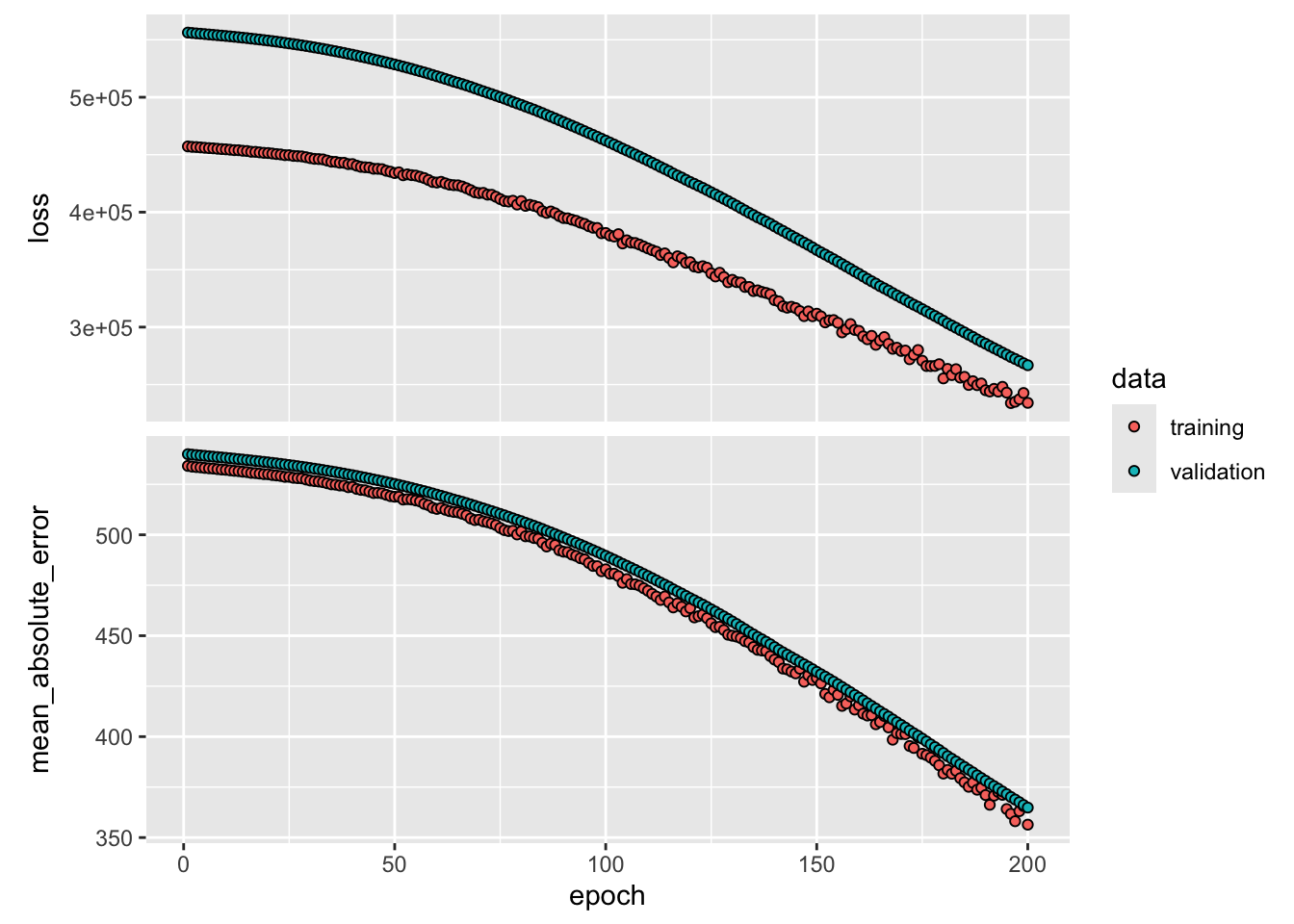
All criteria are steadily declining and have not leveled out after 200 epochs (Figure 35.1). As expected, the mean squared error and mean absolute error are higher in the validation data than in the training data. This is not always the case when training neural networks. Maybe surprisingly, after about 75 epochs the metrics are showing more variability from epoch to epoch in the training data than in the validation data. Also, there is no guarantee that criteria decrease monotonically, the mean squared error of epoch \(t\) can be higher than that of epoch \(t-1\). We are looking for the results to settle down and stabilize before calling the optimization completed. More epochs need to be run in this example. Fortunately, you can continue where the previous run has left off. The following code trains the network for another 100 epochs:
firstANN %>%
fit(x[-testid, ],
y[-testid],
epochs=100,
batch_size=32,
validation_data= list(x[testid, ], y[testid])
)Epoch 1/100
6/6 - 0s - loss: 258880.3594 - mean_absolute_error: 375.3045 - val_loss: 297475.6875 - val_mean_absolute_error: 376.1807 - 16ms/epoch - 3ms/step
Epoch 2/100
6/6 - 0s - loss: 256751.5469 - mean_absolute_error: 374.7601 - val_loss: 295616.8125 - val_mean_absolute_error: 375.0534 - 8ms/epoch - 1ms/step
Epoch 3/100
6/6 - 0s - loss: 255777.5156 - mean_absolute_error: 371.4973 - val_loss: 293809.5938 - val_mean_absolute_error: 373.9495 - 7ms/epoch - 1ms/step
Epoch 4/100
6/6 - 0s - loss: 249313.6094 - mean_absolute_error: 368.7937 - val_loss: 291825.5312 - val_mean_absolute_error: 372.7381 - 7ms/epoch - 1ms/step
Epoch 5/100
6/6 - 0s - loss: 244729.6875 - mean_absolute_error: 366.1051 - val_loss: 289844.9062 - val_mean_absolute_error: 371.5087 - 7ms/epoch - 1ms/step
Epoch 6/100
6/6 - 0s - loss: 246076.1875 - mean_absolute_error: 364.2408 - val_loss: 287988.1875 - val_mean_absolute_error: 370.3609 - 8ms/epoch - 1ms/step
Epoch 7/100
6/6 - 0s - loss: 241271.0938 - mean_absolute_error: 358.6614 - val_loss: 286140.2188 - val_mean_absolute_error: 369.2173 - 7ms/epoch - 1ms/step
Epoch 8/100
6/6 - 0s - loss: 246268.2500 - mean_absolute_error: 365.2642 - val_loss: 284339.5625 - val_mean_absolute_error: 368.0886 - 8ms/epoch - 1ms/step
Epoch 9/100
6/6 - 0s - loss: 246093.2500 - mean_absolute_error: 364.4254 - val_loss: 282652.0312 - val_mean_absolute_error: 367.0087 - 8ms/epoch - 1ms/step
Epoch 10/100
6/6 - 0s - loss: 244343.6875 - mean_absolute_error: 366.0023 - val_loss: 280869.2500 - val_mean_absolute_error: 365.8585 - 8ms/epoch - 1ms/step
Epoch 11/100
6/6 - 0s - loss: 246351.0000 - mean_absolute_error: 364.2267 - val_loss: 279178.4688 - val_mean_absolute_error: 364.7787 - 8ms/epoch - 1ms/step
Epoch 12/100
6/6 - 0s - loss: 241599.3438 - mean_absolute_error: 358.8047 - val_loss: 277446.5625 - val_mean_absolute_error: 363.6575 - 9ms/epoch - 1ms/step
Epoch 13/100
6/6 - 0s - loss: 236925.2656 - mean_absolute_error: 358.4969 - val_loss: 275556.9688 - val_mean_absolute_error: 362.4330 - 8ms/epoch - 1ms/step
Epoch 14/100
6/6 - 0s - loss: 231735.7656 - mean_absolute_error: 356.0421 - val_loss: 273760.8438 - val_mean_absolute_error: 361.2492 - 9ms/epoch - 1ms/step
Epoch 15/100
6/6 - 0s - loss: 242135.3906 - mean_absolute_error: 363.0768 - val_loss: 272021.7500 - val_mean_absolute_error: 360.0959 - 8ms/epoch - 1ms/step
Epoch 16/100
6/6 - 0s - loss: 235721.2656 - mean_absolute_error: 359.2261 - val_loss: 270280.1562 - val_mean_absolute_error: 358.9290 - 8ms/epoch - 1ms/step
Epoch 17/100
6/6 - 0s - loss: 237457.5156 - mean_absolute_error: 356.6158 - val_loss: 268392.3125 - val_mean_absolute_error: 357.6740 - 8ms/epoch - 1ms/step
Epoch 18/100
6/6 - 0s - loss: 235814.0938 - mean_absolute_error: 354.2876 - val_loss: 266752.4062 - val_mean_absolute_error: 356.5650 - 8ms/epoch - 1ms/step
Epoch 19/100
6/6 - 0s - loss: 238556.9375 - mean_absolute_error: 352.4980 - val_loss: 265038.1250 - val_mean_absolute_error: 355.3923 - 8ms/epoch - 1ms/step
Epoch 20/100
6/6 - 0s - loss: 230590.5625 - mean_absolute_error: 353.4418 - val_loss: 263297.1875 - val_mean_absolute_error: 354.2022 - 8ms/epoch - 1ms/step
Epoch 21/100
6/6 - 0s - loss: 229400.3594 - mean_absolute_error: 344.2934 - val_loss: 261740.0000 - val_mean_absolute_error: 353.1277 - 8ms/epoch - 1ms/step
Epoch 22/100
6/6 - 0s - loss: 220324.0000 - mean_absolute_error: 342.1754 - val_loss: 259977.8906 - val_mean_absolute_error: 351.9928 - 8ms/epoch - 1ms/step
Epoch 23/100
6/6 - 0s - loss: 224801.5469 - mean_absolute_error: 348.7812 - val_loss: 258239.2031 - val_mean_absolute_error: 350.8655 - 8ms/epoch - 1ms/step
Epoch 24/100
6/6 - 0s - loss: 237913.1875 - mean_absolute_error: 358.8998 - val_loss: 256513.5625 - val_mean_absolute_error: 349.7483 - 8ms/epoch - 1ms/step
Epoch 25/100
6/6 - 0s - loss: 227879.8438 - mean_absolute_error: 354.2336 - val_loss: 254990.0625 - val_mean_absolute_error: 348.7584 - 8ms/epoch - 1ms/step
Epoch 26/100
6/6 - 0s - loss: 225517.1875 - mean_absolute_error: 343.2806 - val_loss: 253426.4844 - val_mean_absolute_error: 347.7555 - 8ms/epoch - 1ms/step
Epoch 27/100
6/6 - 0s - loss: 222558.7031 - mean_absolute_error: 345.1520 - val_loss: 251774.7188 - val_mean_absolute_error: 346.7078 - 8ms/epoch - 1ms/step
Epoch 28/100
6/6 - 0s - loss: 223793.4062 - mean_absolute_error: 347.4348 - val_loss: 250271.1094 - val_mean_absolute_error: 345.8320 - 8ms/epoch - 1ms/step
Epoch 29/100
6/6 - 0s - loss: 219361.4844 - mean_absolute_error: 342.0196 - val_loss: 248687.5156 - val_mean_absolute_error: 344.9783 - 9ms/epoch - 1ms/step
Epoch 30/100
6/6 - 0s - loss: 226408.8125 - mean_absolute_error: 343.7341 - val_loss: 247301.6094 - val_mean_absolute_error: 344.2432 - 7ms/epoch - 1ms/step
Epoch 31/100
6/6 - 0s - loss: 226730.5625 - mean_absolute_error: 348.1680 - val_loss: 245616.5938 - val_mean_absolute_error: 343.3682 - 7ms/epoch - 1ms/step
Epoch 32/100
6/6 - 0s - loss: 214120.0625 - mean_absolute_error: 338.3702 - val_loss: 244000.4062 - val_mean_absolute_error: 342.5106 - 7ms/epoch - 1ms/step
Epoch 33/100
6/6 - 0s - loss: 212907.1562 - mean_absolute_error: 334.5723 - val_loss: 242630.5000 - val_mean_absolute_error: 341.8004 - 7ms/epoch - 1ms/step
Epoch 34/100
6/6 - 0s - loss: 214797.4844 - mean_absolute_error: 337.4967 - val_loss: 241057.4219 - val_mean_absolute_error: 340.9932 - 7ms/epoch - 1ms/step
Epoch 35/100
6/6 - 0s - loss: 208077.9531 - mean_absolute_error: 336.1927 - val_loss: 239612.6875 - val_mean_absolute_error: 340.2810 - 7ms/epoch - 1ms/step
Epoch 36/100
6/6 - 0s - loss: 217431.3594 - mean_absolute_error: 341.3209 - val_loss: 238066.6875 - val_mean_absolute_error: 339.5290 - 7ms/epoch - 1ms/step
Epoch 37/100
6/6 - 0s - loss: 214843.0156 - mean_absolute_error: 339.2966 - val_loss: 236591.4531 - val_mean_absolute_error: 338.8231 - 8ms/epoch - 1ms/step
Epoch 38/100
6/6 - 0s - loss: 209255.5469 - mean_absolute_error: 326.6752 - val_loss: 234913.7188 - val_mean_absolute_error: 337.9958 - 8ms/epoch - 1ms/step
Epoch 39/100
6/6 - 0s - loss: 210502.2031 - mean_absolute_error: 333.8434 - val_loss: 233577.8438 - val_mean_absolute_error: 337.3397 - 7ms/epoch - 1ms/step
Epoch 40/100
6/6 - 0s - loss: 214537.3906 - mean_absolute_error: 335.0873 - val_loss: 232189.7500 - val_mean_absolute_error: 336.6487 - 8ms/epoch - 1ms/step
Epoch 41/100
6/6 - 0s - loss: 213792.0469 - mean_absolute_error: 334.9817 - val_loss: 230826.4844 - val_mean_absolute_error: 335.9688 - 7ms/epoch - 1ms/step
Epoch 42/100
6/6 - 0s - loss: 213513.4531 - mean_absolute_error: 340.0223 - val_loss: 229577.4531 - val_mean_absolute_error: 335.3430 - 8ms/epoch - 1ms/step
Epoch 43/100
6/6 - 0s - loss: 204561.3906 - mean_absolute_error: 327.2233 - val_loss: 228211.3125 - val_mean_absolute_error: 334.6400 - 8ms/epoch - 1ms/step
Epoch 44/100
6/6 - 0s - loss: 206182.8125 - mean_absolute_error: 331.4399 - val_loss: 226660.7188 - val_mean_absolute_error: 333.8402 - 7ms/epoch - 1ms/step
Epoch 45/100
6/6 - 0s - loss: 207485.6406 - mean_absolute_error: 331.6845 - val_loss: 225206.7656 - val_mean_absolute_error: 333.0811 - 7ms/epoch - 1ms/step
Epoch 46/100
6/6 - 0s - loss: 206374.1094 - mean_absolute_error: 334.8417 - val_loss: 223892.7344 - val_mean_absolute_error: 332.4042 - 8ms/epoch - 1ms/step
Epoch 47/100
6/6 - 0s - loss: 206365.5938 - mean_absolute_error: 329.2446 - val_loss: 222660.5000 - val_mean_absolute_error: 331.8268 - 7ms/epoch - 1ms/step
Epoch 48/100
6/6 - 0s - loss: 204432.9062 - mean_absolute_error: 329.2296 - val_loss: 221392.8438 - val_mean_absolute_error: 331.2288 - 7ms/epoch - 1ms/step
Epoch 49/100
6/6 - 0s - loss: 208290.0469 - mean_absolute_error: 337.0822 - val_loss: 220222.2812 - val_mean_absolute_error: 330.6724 - 7ms/epoch - 1ms/step
Epoch 50/100
6/6 - 0s - loss: 199046.4531 - mean_absolute_error: 326.8019 - val_loss: 218807.0781 - val_mean_absolute_error: 329.9893 - 7ms/epoch - 1ms/step
Epoch 51/100
6/6 - 0s - loss: 196617.0469 - mean_absolute_error: 324.4510 - val_loss: 217404.5469 - val_mean_absolute_error: 329.3045 - 7ms/epoch - 1ms/step
Epoch 52/100
6/6 - 0s - loss: 204368.3438 - mean_absolute_error: 328.7074 - val_loss: 216106.6250 - val_mean_absolute_error: 328.6642 - 8ms/epoch - 1ms/step
Epoch 53/100
6/6 - 0s - loss: 197242.2344 - mean_absolute_error: 324.7093 - val_loss: 215183.4531 - val_mean_absolute_error: 328.2142 - 7ms/epoch - 1ms/step
Epoch 54/100
6/6 - 0s - loss: 194651.0469 - mean_absolute_error: 326.3214 - val_loss: 213991.3281 - val_mean_absolute_error: 327.6316 - 7ms/epoch - 1ms/step
Epoch 55/100
6/6 - 0s - loss: 199338.8438 - mean_absolute_error: 327.5460 - val_loss: 212689.4219 - val_mean_absolute_error: 327.0045 - 8ms/epoch - 1ms/step
Epoch 56/100
6/6 - 0s - loss: 192101.8906 - mean_absolute_error: 319.8718 - val_loss: 211649.8438 - val_mean_absolute_error: 326.4977 - 7ms/epoch - 1ms/step
Epoch 57/100
6/6 - 0s - loss: 205305.4844 - mean_absolute_error: 330.7862 - val_loss: 210685.1094 - val_mean_absolute_error: 326.0192 - 7ms/epoch - 1ms/step
Epoch 58/100
6/6 - 0s - loss: 196010.8594 - mean_absolute_error: 324.7750 - val_loss: 209605.2344 - val_mean_absolute_error: 325.5022 - 8ms/epoch - 1ms/step
Epoch 59/100
6/6 - 0s - loss: 186569.8281 - mean_absolute_error: 315.4674 - val_loss: 208234.6875 - val_mean_absolute_error: 324.8099 - 8ms/epoch - 1ms/step
Epoch 60/100
6/6 - 0s - loss: 194796.2969 - mean_absolute_error: 325.1953 - val_loss: 207294.1562 - val_mean_absolute_error: 324.3479 - 7ms/epoch - 1ms/step
Epoch 61/100
6/6 - 0s - loss: 196980.6094 - mean_absolute_error: 323.9706 - val_loss: 206250.1562 - val_mean_absolute_error: 323.8232 - 7ms/epoch - 1ms/step
Epoch 62/100
6/6 - 0s - loss: 187126.2656 - mean_absolute_error: 313.1653 - val_loss: 204793.7969 - val_mean_absolute_error: 323.0809 - 7ms/epoch - 1ms/step
Epoch 63/100
6/6 - 0s - loss: 187161.9688 - mean_absolute_error: 318.9101 - val_loss: 203629.5469 - val_mean_absolute_error: 322.4954 - 8ms/epoch - 1ms/step
Epoch 64/100
6/6 - 0s - loss: 193797.5000 - mean_absolute_error: 323.5721 - val_loss: 202632.3281 - val_mean_absolute_error: 321.9650 - 7ms/epoch - 1ms/step
Epoch 65/100
6/6 - 0s - loss: 191985.1094 - mean_absolute_error: 321.3331 - val_loss: 201626.1406 - val_mean_absolute_error: 321.4546 - 7ms/epoch - 1ms/step
Epoch 66/100
6/6 - 0s - loss: 194798.4062 - mean_absolute_error: 322.4000 - val_loss: 200489.3125 - val_mean_absolute_error: 320.8526 - 7ms/epoch - 1ms/step
Epoch 67/100
6/6 - 0s - loss: 185644.0938 - mean_absolute_error: 320.0219 - val_loss: 199406.1562 - val_mean_absolute_error: 320.2717 - 7ms/epoch - 1ms/step
Epoch 68/100
6/6 - 0s - loss: 185774.6250 - mean_absolute_error: 316.5340 - val_loss: 198412.3750 - val_mean_absolute_error: 319.7606 - 7ms/epoch - 1ms/step
Epoch 69/100
6/6 - 0s - loss: 190631.3594 - mean_absolute_error: 321.1985 - val_loss: 197413.7031 - val_mean_absolute_error: 319.2157 - 7ms/epoch - 1ms/step
Epoch 70/100
6/6 - 0s - loss: 187575.9375 - mean_absolute_error: 313.9200 - val_loss: 196420.5938 - val_mean_absolute_error: 318.6824 - 7ms/epoch - 1ms/step
Epoch 71/100
6/6 - 0s - loss: 186168.0156 - mean_absolute_error: 315.1212 - val_loss: 195296.7812 - val_mean_absolute_error: 318.0636 - 7ms/epoch - 1ms/step
Epoch 72/100
6/6 - 0s - loss: 187220.0938 - mean_absolute_error: 320.1799 - val_loss: 194306.2031 - val_mean_absolute_error: 317.5211 - 7ms/epoch - 1ms/step
Epoch 73/100
6/6 - 0s - loss: 191761.2969 - mean_absolute_error: 324.7582 - val_loss: 193452.0156 - val_mean_absolute_error: 317.0453 - 7ms/epoch - 1ms/step
Epoch 74/100
6/6 - 0s - loss: 183467.3125 - mean_absolute_error: 311.9371 - val_loss: 192503.7656 - val_mean_absolute_error: 316.5184 - 7ms/epoch - 1ms/step
Epoch 75/100
6/6 - 0s - loss: 183126.1875 - mean_absolute_error: 311.0605 - val_loss: 191548.6719 - val_mean_absolute_error: 315.9785 - 8ms/epoch - 1ms/step
Epoch 76/100
6/6 - 0s - loss: 178636.6562 - mean_absolute_error: 312.9312 - val_loss: 190818.8281 - val_mean_absolute_error: 315.5816 - 7ms/epoch - 1ms/step
Epoch 77/100
6/6 - 0s - loss: 181877.0625 - mean_absolute_error: 312.0493 - val_loss: 189868.3281 - val_mean_absolute_error: 315.0317 - 7ms/epoch - 1ms/step
Epoch 78/100
6/6 - 0s - loss: 180342.2344 - mean_absolute_error: 313.4308 - val_loss: 188733.0781 - val_mean_absolute_error: 314.3662 - 7ms/epoch - 1ms/step
Epoch 79/100
6/6 - 0s - loss: 175019.6875 - mean_absolute_error: 306.1186 - val_loss: 187817.2656 - val_mean_absolute_error: 313.8326 - 7ms/epoch - 1ms/step
Epoch 80/100
6/6 - 0s - loss: 171485.2500 - mean_absolute_error: 304.8706 - val_loss: 186691.4844 - val_mean_absolute_error: 313.1514 - 7ms/epoch - 1ms/step
Epoch 81/100
6/6 - 0s - loss: 176977.9531 - mean_absolute_error: 309.1890 - val_loss: 185821.5469 - val_mean_absolute_error: 312.6214 - 8ms/epoch - 1ms/step
Epoch 82/100
6/6 - 0s - loss: 179251.1250 - mean_absolute_error: 315.2583 - val_loss: 184924.4219 - val_mean_absolute_error: 312.0843 - 7ms/epoch - 1ms/step
Epoch 83/100
6/6 - 0s - loss: 177606.3594 - mean_absolute_error: 312.3251 - val_loss: 184186.9531 - val_mean_absolute_error: 311.6501 - 8ms/epoch - 1ms/step
Epoch 84/100
6/6 - 0s - loss: 171053.0156 - mean_absolute_error: 307.3180 - val_loss: 183296.5469 - val_mean_absolute_error: 311.1140 - 7ms/epoch - 1ms/step
Epoch 85/100
6/6 - 0s - loss: 170275.5625 - mean_absolute_error: 303.2836 - val_loss: 182422.4688 - val_mean_absolute_error: 310.5975 - 7ms/epoch - 1ms/step
Epoch 86/100
6/6 - 0s - loss: 165835.2656 - mean_absolute_error: 303.6604 - val_loss: 181520.2344 - val_mean_absolute_error: 310.0499 - 8ms/epoch - 1ms/step
Epoch 87/100
6/6 - 0s - loss: 173186.0938 - mean_absolute_error: 306.7030 - val_loss: 180675.2188 - val_mean_absolute_error: 309.5330 - 7ms/epoch - 1ms/step
Epoch 88/100
6/6 - 0s - loss: 172217.4844 - mean_absolute_error: 303.4867 - val_loss: 179789.2031 - val_mean_absolute_error: 309.0034 - 7ms/epoch - 1ms/step
Epoch 89/100
6/6 - 0s - loss: 165754.4531 - mean_absolute_error: 302.3290 - val_loss: 179031.3594 - val_mean_absolute_error: 308.5298 - 7ms/epoch - 1ms/step
Epoch 90/100
6/6 - 0s - loss: 176261.1094 - mean_absolute_error: 314.1570 - val_loss: 178433.7188 - val_mean_absolute_error: 308.1630 - 7ms/epoch - 1ms/step
Epoch 91/100
6/6 - 0s - loss: 165713.2969 - mean_absolute_error: 301.2115 - val_loss: 177510.2500 - val_mean_absolute_error: 307.5928 - 7ms/epoch - 1ms/step
Epoch 92/100
6/6 - 0s - loss: 179247.5156 - mean_absolute_error: 308.9620 - val_loss: 176846.2344 - val_mean_absolute_error: 307.1672 - 7ms/epoch - 1ms/step
Epoch 93/100
6/6 - 0s - loss: 168949.2656 - mean_absolute_error: 307.8897 - val_loss: 176291.9375 - val_mean_absolute_error: 306.8170 - 7ms/epoch - 1ms/step
Epoch 94/100
6/6 - 0s - loss: 176287.6875 - mean_absolute_error: 308.5885 - val_loss: 175757.4844 - val_mean_absolute_error: 306.4785 - 7ms/epoch - 1ms/step
Epoch 95/100
6/6 - 0s - loss: 161662.0156 - mean_absolute_error: 297.2891 - val_loss: 174975.1250 - val_mean_absolute_error: 305.9691 - 7ms/epoch - 1ms/step
Epoch 96/100
6/6 - 0s - loss: 180840.2812 - mean_absolute_error: 313.8895 - val_loss: 174446.2500 - val_mean_absolute_error: 305.6442 - 7ms/epoch - 1ms/step
Epoch 97/100
6/6 - 0s - loss: 166233.2344 - mean_absolute_error: 301.1301 - val_loss: 173697.0312 - val_mean_absolute_error: 305.1224 - 7ms/epoch - 1ms/step
Epoch 98/100
6/6 - 0s - loss: 174210.4844 - mean_absolute_error: 309.4707 - val_loss: 173164.8906 - val_mean_absolute_error: 304.7771 - 7ms/epoch - 1ms/step
Epoch 99/100
6/6 - 0s - loss: 163274.5469 - mean_absolute_error: 300.5897 - val_loss: 172603.6562 - val_mean_absolute_error: 304.4324 - 7ms/epoch - 1ms/step
Epoch 100/100
6/6 - 0s - loss: 171079.6094 - mean_absolute_error: 306.1794 - val_loss: 171926.2344 - val_mean_absolute_error: 303.9624 - 7ms/epoch - 1ms/stepWhen training models this way you keep your eyes on the epoch history to study the behavior of the loss function and other metrics on training and test data sets. You have to make a judgement call as to when the optimization has stabilized and further progress is minimal. Alternatively, you can install a function that stops the optimization when certain conditions are met.
This is done in the following code with the callback_early_stopping callback function (not run here). The options of the early stopping function ask it to monitor the loss function on the validation data and stop the optimization when the criterion fails to decrease (mode="min") over 10 epochs (patience=10). Any change of the monitored metric has to be at least 0.1 in magnitude to qualify as an improvement (min_delta=.1).
early_stopping <- callback_early_stopping(monitor = 'val_loss',
patience = 10,
min_delta = .1,
mode="min")
firstANN %>%
fit(x[-testid, ],
y[-testid],
epochs=400,
batch_size=32,
validation_data= list(x[testid, ], y[testid])
callbacks=c(early_stopping)
)To see a list of all Keras callback functions type the following at the console prompt:
?keras::callFinally, we predict from the final model, and evaluate its performance on the test data. Due to the use of random elements in the fit (stochastic gradient descent, random dropout, …), the results vary slightly with each fit. Unfortunately the set.seed() function does not ensure identical results (since the fitting is done in python), so your results will differ slightly.
predvals <- predict(firstANN, x[testid, ])3/3 - 0s - 17ms/epoch - 6ms/stepmean(abs(y[testid] - predvals))[1] 303.9624Random numbers
An aspect of Keras that can be befuddling to R users is lack of control over the random mechanisms during training. Neural networks rely on random numbers for picking starting values, selecting observations into mini batches, selecting neurons in dropout layers, etc.
Since the code executes in Python, the set.seed() operation alone does not have the intended effect of fixing the sequence of generated random numbers. The underlying Python code relies on random number generators from the Random and Numpy packages. TensorFlow has its own random number generator on top of that. Python code that uses Keras with the TensorFlow backend needs to set a seed for each generator to obtain reproducible results. The tensorflow function set_random_seed sets a seed value for both the R environment and the Python environment random number generators to increase reproducibility.
tensorflow::set_random_seed(2, disable_gpu = TRUE)Keras might still generate non-reproducible results. For example, multi-threading operations on CPUs—and GPUs in particular—can produce a non-deterministic order of operations. The diable_gpu argument of set_random_seed function can be set to TRUE to increase reproducibility but performance may suffer.
Even with these controls, results may vary slightly. One recommendation to deal with non-deterministic results is training the model several times and averaging the results, essentially ensembling them. When a single training run takes several hours, doing it thirty times is not practical.
MNIST Image Classification
We now return to the MNIST image classification data introduced in Section 32.4. Recall that the data comprise 60,000 training images and 10,000 test images of handwritten digits (0–9). Each image has 28 x 28 pixels recording a grayscale value.
The MNIST data is provided by Keras:
Setup the data
mnist <- dataset_mnist()
x_train <- mnist$train$x
g_train <- mnist$train$y
x_test <- mnist$test$x
g_test <- mnist$test$y
dim(x_train)[1] 60000 28 28dim(x_test)[1] 10000 28 28The images are stored as a three-dimensional array, and need to be reshaped into a matrix. For classification tasks with \(k\) categories, Keras expects as the target values a matrix of \(k\) columns. Column \(k\) contains ones in the rows for observations where the observed category is \(k\), and zeros otherwise. This is called one-hot encoding of the target variable. Luckily, keras has built-in functions that handle both tasks for us.
x_train <- array_reshape(x_train, c(nrow(x_train), 784))
x_test <- array_reshape(x_test, c(nrow(x_test), 784))
y_train <- to_categorical(g_train, 10)
y_test <- to_categorical(g_test, 10)Let’s look at the one-hot encoding of the target data. g_test contains the value of the digit from 0–9. y_test is a matrix with 10 columns, each column corresponds to one digit. If observation \(i\) represents digit \(j\) then there is a 1 in row \(i\), column \(j+1\) of the encoded matrix. For example, for the first twenty images:
g_test[1:20] [1] 7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4y_test[1:20,1:10] [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0 0 0 0 1 0 0
[2,] 0 0 1 0 0 0 0 0 0 0
[3,] 0 1 0 0 0 0 0 0 0 0
[4,] 1 0 0 0 0 0 0 0 0 0
[5,] 0 0 0 0 1 0 0 0 0 0
[6,] 0 1 0 0 0 0 0 0 0 0
[7,] 0 0 0 0 1 0 0 0 0 0
[8,] 0 0 0 0 0 0 0 0 0 1
[9,] 0 0 0 0 0 1 0 0 0 0
[10,] 0 0 0 0 0 0 0 0 0 1
[11,] 1 0 0 0 0 0 0 0 0 0
[12,] 0 0 0 0 0 0 1 0 0 0
[13,] 0 0 0 0 0 0 0 0 0 1
[14,] 1 0 0 0 0 0 0 0 0 0
[15,] 0 1 0 0 0 0 0 0 0 0
[16,] 0 0 0 0 0 1 0 0 0 0
[17,] 0 0 0 0 0 0 0 0 0 1
[18,] 0 0 0 0 0 0 0 1 0 0
[19,] 0 0 0 1 0 0 0 0 0 0
[20,] 0 0 0 0 1 0 0 0 0 0Let’s look at the matrix of inputs. The next array shows the 28 x 28 - 784 input columns for the third image. The values are grayscale values between 0 and 255.
x_test[3,] [1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[19] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[37] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[55] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[73] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[91] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[109] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[127] 0 0 38 254 109 0 0 0 0 0 0 0 0 0 0 0 0 0
[145] 0 0 0 0 0 0 0 0 0 0 0 0 87 252 82 0 0 0
[163] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[181] 0 0 0 0 135 241 0 0 0 0 0 0 0 0 0 0 0 0
[199] 0 0 0 0 0 0 0 0 0 0 0 0 0 45 244 150 0 0
[217] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[235] 0 0 0 0 0 84 254 63 0 0 0 0 0 0 0 0 0 0
[253] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 202 223 11
[271] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[289] 0 0 0 0 0 0 32 254 216 0 0 0 0 0 0 0 0 0
[307] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 95 254
[325] 195 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[343] 0 0 0 0 0 0 0 0 140 254 77 0 0 0 0 0 0 0
[361] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 57
[379] 237 205 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[397] 0 0 0 0 0 0 0 0 0 124 255 165 0 0 0 0 0 0
[415] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[433] 0 171 254 81 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[451] 0 0 0 0 0 0 0 0 0 0 24 232 215 0 0 0 0 0
[469] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[487] 0 0 120 254 159 0 0 0 0 0 0 0 0 0 0 0 0 0
[505] 0 0 0 0 0 0 0 0 0 0 0 0 151 254 142 0 0 0
[523] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[541] 0 0 0 0 228 254 66 0 0 0 0 0 0 0 0 0 0 0
[559] 0 0 0 0 0 0 0 0 0 0 0 0 0 61 251 254 66 0
[577] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[595] 0 0 0 0 0 141 254 205 3 0 0 0 0 0 0 0 0 0
[613] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 215 254 121
[631] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[649] 0 0 0 0 0 0 5 198 176 10 0 0 0 0 0 0 0 0
[667] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[685] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[703] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[721] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[739] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[757] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[775] 0 0 0 0 0 0 0 0 0 0Finally, prior to training the network, we scale the input values to lie between 0–1.
x_train <- x_train / 255
x_test <- x_test / 255The target variable does not need to be scaled, the one-hot encoding together with the use of a softmax output function ensures that the output for each category is a value between 0 and 1, and that they sum to 1 across the 10 categories. We will interpret them as predicted probabilities that an observed image is assigned to a particular digit.
To classify the MNIST images we consider two types of neural networks in the remainder of this chapter: a multi layer ANN and a network without a hidden layer. The latter is a multi category perceptron and very similar to a multinomial logistic regression model.
Multi layer neural network
We now train the network shown in Figure 32.14, an ANN with two hidden layers. We also add dropout regularization layers after each fully connected hidden layer. The first layer specifies the input shape of 28 x 28 = 784. It has 128 neurons and ReLU activation. Why? Because.
This is followed by a first dropout layer with rate \(\phi_1 = 0.3\), another fully connected hidden layer with 64 nodes and hyperbolic tangent activation function, a second dropout layer with rate \(\phi_2 = 0.2\), and a final softmax output layer. Why? Because.
Setup the network
The following statements set up the network in keras:
modelnn <- keras_model_sequential() %>%
layer_dense(units=128,
activation="relu",
input_shape=784,
name="FirstHidden") %>%
layer_dropout(rate=0.3,
name="FirstDropOut") %>%
layer_dense(units=64,
activation="tanh",
name="SecondHidden") %>%
layer_dropout(rate=0.2,
name="SecondDropOut") %>%
layer_dense(units=10,
activation="softmax",
name="Output")The summary() function let’s us inspect whether we got it all right.
summary(modelnn)Model: "sequential_1"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
FirstHidden (Dense) (None, 128) 100480
FirstDropOut (Dropout) (None, 128) 0
SecondHidden (Dense) (None, 64) 8256
SecondDropOut (Dropout) (None, 64) 0
Output (Dense) (None, 10) 650
================================================================================
Total params: 109386 (427.29 KB)
Trainable params: 109386 (427.29 KB)
Non-trainable params: 0 (0.00 Byte)
________________________________________________________________________________The total number of parameters in this network is 109,386, a sizeable network but not a huge network.
Set up the optimization
Next, we add details to the model to specify the fitting algorithm. We fit the model by minimizing the categorical cross-entropy function and monitor the classification accuracy during the iterations.
modelnn %>% compile(loss="categorical_crossentropy",
optimizer=optimizer_rmsprop(),
metrics=c("accuracy")
)Fit the model
We are ready to go. The final step is to supply training data, and fit the model. With a batch size of 128 observations, each epoch corresponds to 60,000 / 128 = 469 gradient evaluations.
history <- modelnn %>%
fit(x_train,
y_train,
epochs=20,
batch_size=128,
validation_data= list(x_test, y_test),
)Epoch 1/20
469/469 - 1s - loss: 0.3979 - accuracy: 0.8844 - val_loss: 0.1681 - val_accuracy: 0.9466 - 561ms/epoch - 1ms/step
Epoch 2/20
469/469 - 0s - loss: 0.1871 - accuracy: 0.9450 - val_loss: 0.1213 - val_accuracy: 0.9637 - 418ms/epoch - 891us/step
Epoch 3/20
469/469 - 0s - loss: 0.1467 - accuracy: 0.9559 - val_loss: 0.1054 - val_accuracy: 0.9680 - 413ms/epoch - 880us/step
Epoch 4/20
469/469 - 0s - loss: 0.1252 - accuracy: 0.9632 - val_loss: 0.0887 - val_accuracy: 0.9734 - 425ms/epoch - 906us/step
Epoch 5/20
469/469 - 0s - loss: 0.1108 - accuracy: 0.9666 - val_loss: 0.0854 - val_accuracy: 0.9739 - 419ms/epoch - 894us/step
Epoch 6/20
469/469 - 0s - loss: 0.1010 - accuracy: 0.9701 - val_loss: 0.0801 - val_accuracy: 0.9753 - 418ms/epoch - 890us/step
Epoch 7/20
469/469 - 0s - loss: 0.0933 - accuracy: 0.9721 - val_loss: 0.0815 - val_accuracy: 0.9783 - 412ms/epoch - 879us/step
Epoch 8/20
469/469 - 0s - loss: 0.0877 - accuracy: 0.9729 - val_loss: 0.0791 - val_accuracy: 0.9783 - 416ms/epoch - 887us/step
Epoch 9/20
469/469 - 0s - loss: 0.0824 - accuracy: 0.9747 - val_loss: 0.0759 - val_accuracy: 0.9793 - 411ms/epoch - 877us/step
Epoch 10/20
469/469 - 0s - loss: 0.0790 - accuracy: 0.9751 - val_loss: 0.0715 - val_accuracy: 0.9795 - 410ms/epoch - 875us/step
Epoch 11/20
469/469 - 0s - loss: 0.0760 - accuracy: 0.9766 - val_loss: 0.0738 - val_accuracy: 0.9798 - 411ms/epoch - 877us/step
Epoch 12/20
469/469 - 0s - loss: 0.0719 - accuracy: 0.9778 - val_loss: 0.0754 - val_accuracy: 0.9786 - 417ms/epoch - 890us/step
Epoch 13/20
469/469 - 0s - loss: 0.0678 - accuracy: 0.9792 - val_loss: 0.0757 - val_accuracy: 0.9793 - 415ms/epoch - 885us/step
Epoch 14/20
469/469 - 0s - loss: 0.0651 - accuracy: 0.9800 - val_loss: 0.0740 - val_accuracy: 0.9786 - 406ms/epoch - 866us/step
Epoch 15/20
469/469 - 0s - loss: 0.0651 - accuracy: 0.9793 - val_loss: 0.0730 - val_accuracy: 0.9808 - 417ms/epoch - 889us/step
Epoch 16/20
469/469 - 0s - loss: 0.0613 - accuracy: 0.9810 - val_loss: 0.0709 - val_accuracy: 0.9803 - 413ms/epoch - 880us/step
Epoch 17/20
469/469 - 0s - loss: 0.0613 - accuracy: 0.9806 - val_loss: 0.0691 - val_accuracy: 0.9814 - 410ms/epoch - 874us/step
Epoch 18/20
469/469 - 0s - loss: 0.0575 - accuracy: 0.9812 - val_loss: 0.0767 - val_accuracy: 0.9799 - 412ms/epoch - 878us/step
Epoch 19/20
469/469 - 0s - loss: 0.0553 - accuracy: 0.9823 - val_loss: 0.0714 - val_accuracy: 0.9811 - 475ms/epoch - 1ms/step
Epoch 20/20
469/469 - 0s - loss: 0.0542 - accuracy: 0.9832 - val_loss: 0.0695 - val_accuracy: 0.9811 - 416ms/epoch - 887us/stepplot(history, smooth = FALSE)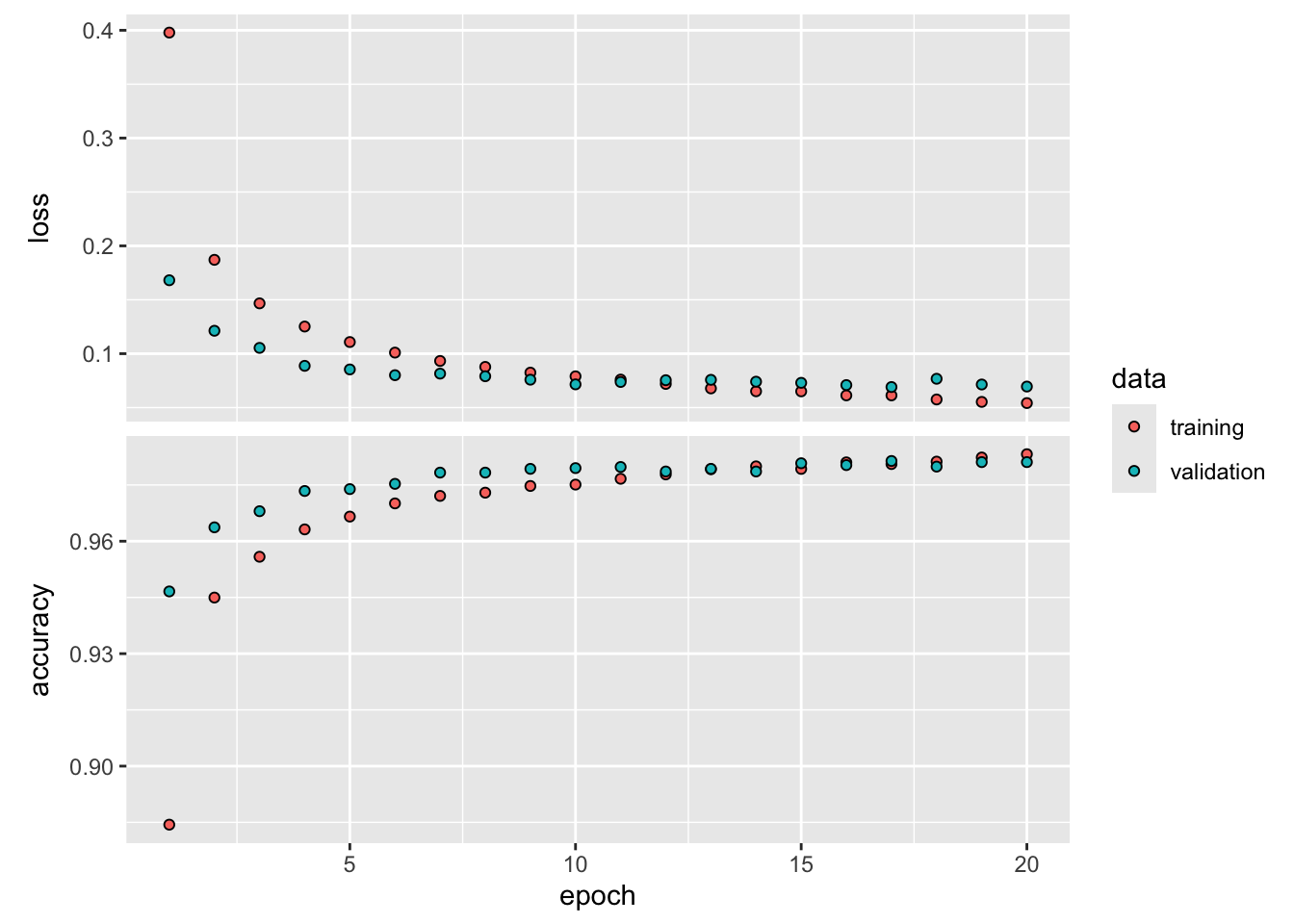
After about 10 epochs the training and validation accuracy are stabilizing although the loss continues to decrease. Interestingly, the accuracy and loss in the 10,000 image validation set is better than in the 60,000 image training data set. Considering that the grayscale values are entered into this neural network as 784 numeric input variables without taking into account any spatial arrangement of the pixels on the image, a classification accuracy of 96% on unseen images is quite good. Whether that is sufficient depends on the application.
As we will see in Chapter 36, neural networks that specialize in the processing of grid-like data such as images easily improve on this performance.
Calculate predicted categories
To calculate the predicted categories for the images in the test data set, we use the predict function. The result of that operation is a vector of 10 predicted probabilities for each observation.
predvals <- modelnn %>% predict(x_test)313/313 - 0s - 81ms/epoch - 258us/stepFor the first image, the probabilities that its digit belongs to any of the 10 classes is given by this vector
round(predvals[1,],4) [1] 0 0 0 0 0 0 0 1 0 0which.max(predvals[1,])[1] 8The maximum probability is 1 in position 8. The image is classified as a “7” (the digits are 0-based).
keras provides the convenience function k_argmax() to perform this operation; it returns the index of the maximum value:
predcl <- modelnn %>% predict(x_test) %>% k_argmax() 313/313 - 0s - 75ms/epoch - 240us/stepWhich of the first 500 observations were misclassified?
miscl <- which(as.numeric(predcl[1:500]) != g_test[1:500])
miscl[1] 248 260 322 341 360 382 446cat("Observed value for obs # ", miscl[1], ":", g_test[miscl[1]],"\n")Observed value for obs # 248 : 4 cat("Predicted value for obs #", miscl[1], ":", as.numeric(predcl[miscl[1]]))Predicted value for obs # 248 : 2The first misclassified observation is #248. The observed digit value is 4, the predicted value is 2. The softmax probabilities for this observation show why it predicted category 2:
round(predvals[miscl[1],],4) [1] 0.0000 0.0003 0.9791 0.0001 0.0039 0.0003 0.0159 0.0002 0.0001 0.0000We can visualize the data with the image function. The next code segment does this for the first observation in the data set and for the first two mis-classified observations:
# visualize the digits
plotIt <- function(id=1) {
im <- mnist$test$x[id,,]
im <- t(apply(im, 2, rev))
image(1:28, 1:28,
im,
col=gray((0:255)/255),
xaxt='n',
main=paste("Observation #",id,"--",
"Image label: ",g_test[id],
" Predicted: ", as.numeric(predcl[id])))
}
plotIt(1)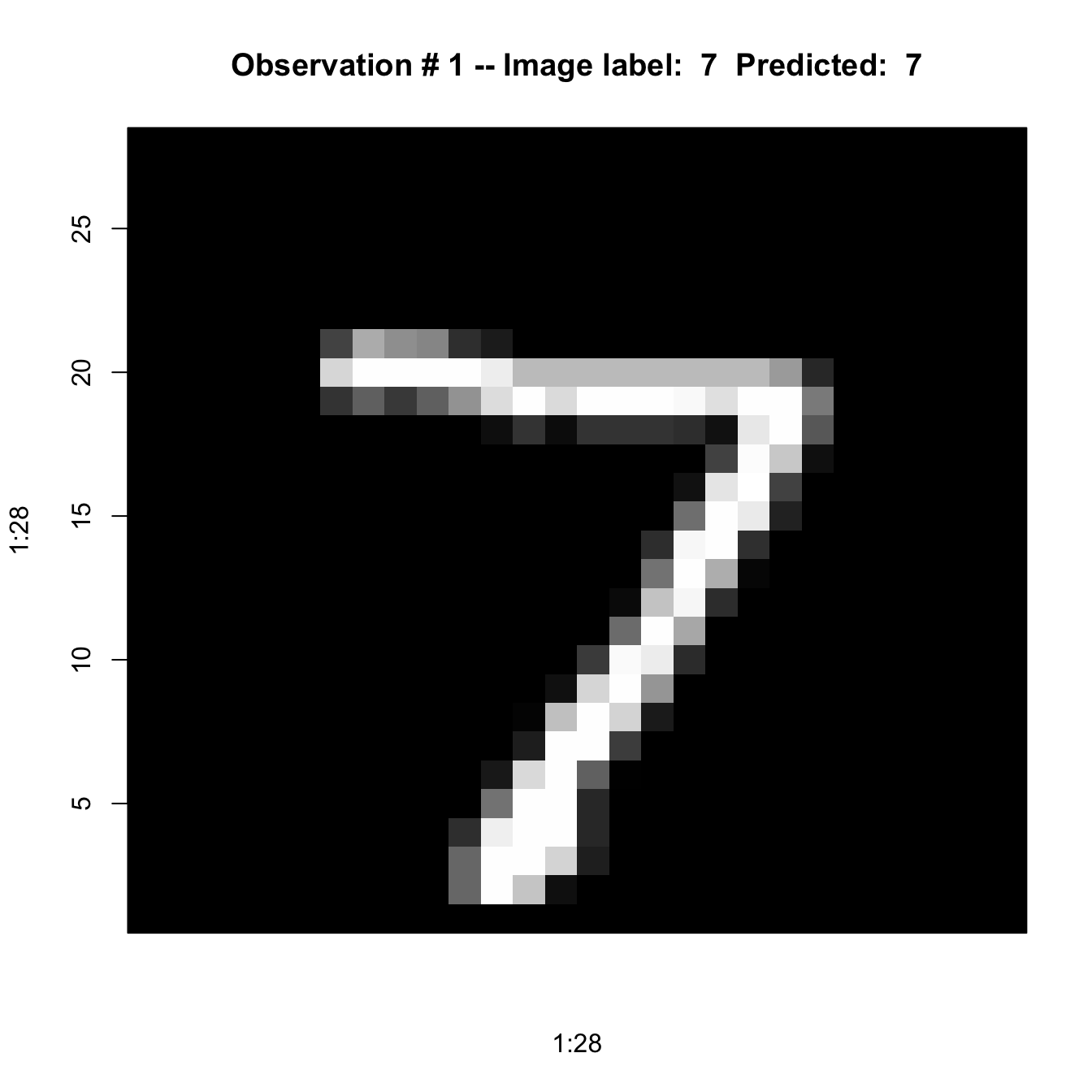
plotIt(miscl[1])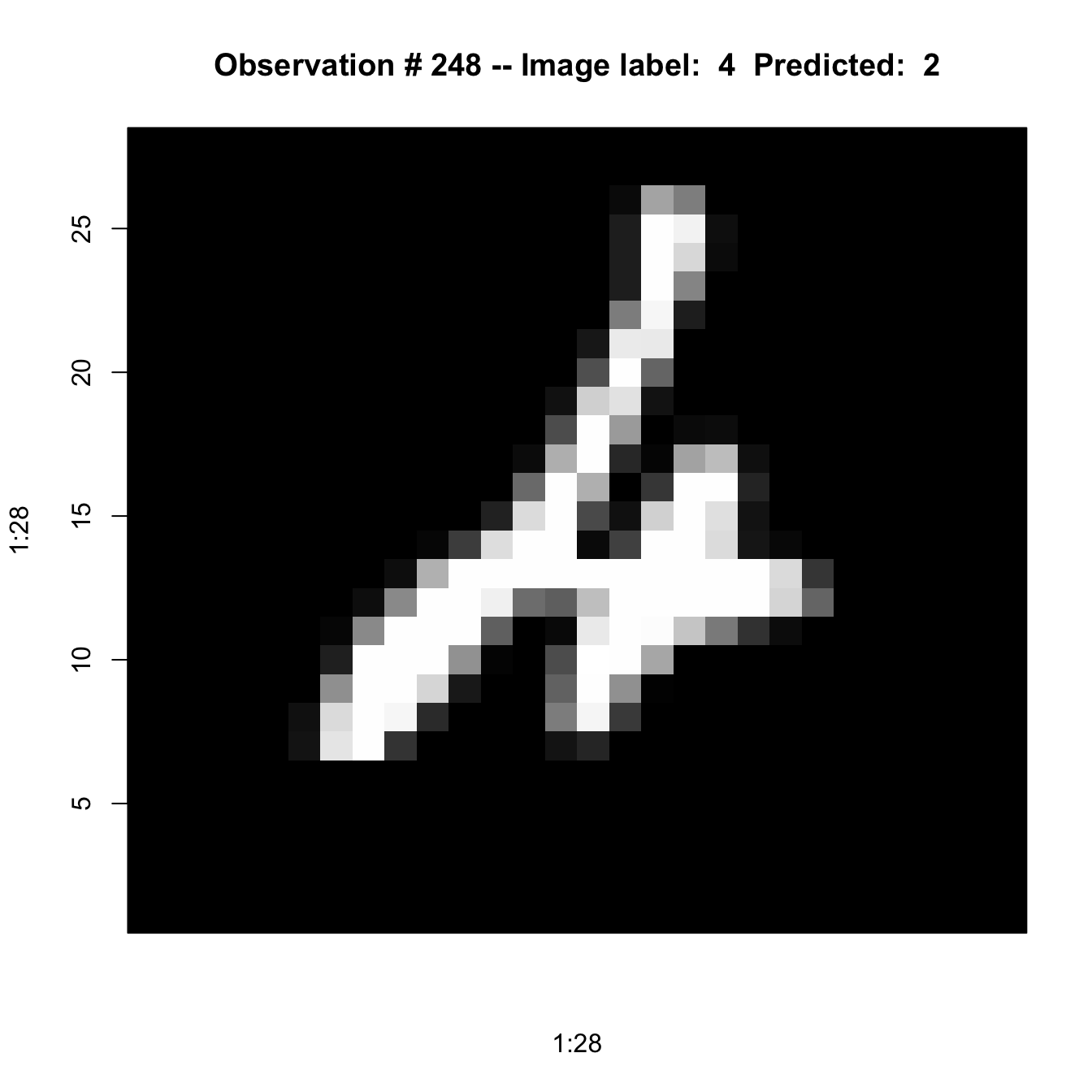
plotIt(miscl[2])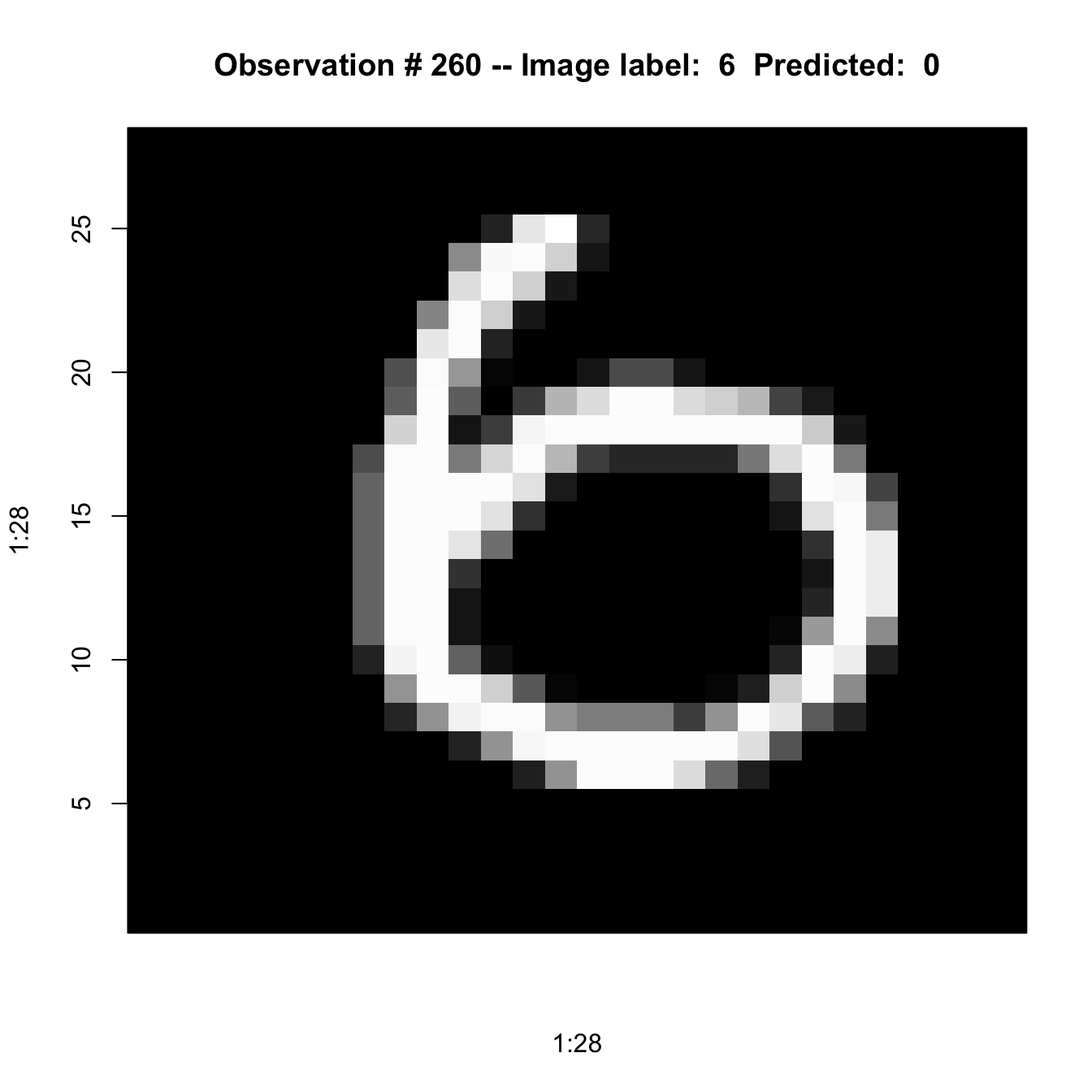
Multinomial logistic regression
A 98% accuracy is impressive, but maybe it is not good enough. In applications where the consequences of errors are high, this accuracy might be insufficient. Suppose we are using the trained network to recognize written digits on personal checks. Getting 200 out of 10,000 digits wrong would be unacceptable. Banks would deposit incorrect amounts all the time.
If that is the application for the trained algorithm, we should consider other models for these data. This raises an interesting question: how much did we gain by adding the layers of the network? If this is an effective strategy to increase accuracy then we could consider adding more layers. If not, then maybe we need to research an entirely different network architecture.
Before trying deeper alternatives we can establish one performance benchmark by removing the hidden layers and training what essentially is a single layer perceptron (Section 32.1). This model has an input layer and an output layer. In terms of the keras syntax it is specified with a single layer:
modellr <- keras_model_sequential() %>%
layer_dense(input_shape=784,
units=10,
activation="softmax")
summary(modellr)Model: "sequential_2"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
dense_1 (Dense) (None, 10) 7850
================================================================================
Total params: 7850 (30.66 KB)
Trainable params: 7850 (30.66 KB)
Non-trainable params: 0 (0.00 Byte)
________________________________________________________________________________This is essentially a multinomial logistic regression model with a 10-category target variable and 784 input variables. The model is much smaller than the previous network (it has only 7,850 parameters) but is huge if we think of it as a multinomial logistic regression model. Many software packages for multinomial regression would struggle to fit a model of this size. When articulated as a neural network, training such a model is actually a breeze.
We proceed just as before.
modellr %>% compile(loss = "categorical_crossentropy",
optimizer = optimizer_rmsprop(),
metrics = c("accuracy"))
history_lr <- modellr %>% fit(x_train,
y_train,
epochs=20,
batch_size=128,
validation_data=list(x_test, y_test))Epoch 1/20
469/469 - 0s - loss: 0.6031 - accuracy: 0.8491 - val_loss: 0.3453 - val_accuracy: 0.9080 - 275ms/epoch - 585us/step
Epoch 2/20
469/469 - 0s - loss: 0.3331 - accuracy: 0.9074 - val_loss: 0.2994 - val_accuracy: 0.9171 - 183ms/epoch - 390us/step
Epoch 3/20
469/469 - 0s - loss: 0.3044 - accuracy: 0.9152 - val_loss: 0.2878 - val_accuracy: 0.9208 - 177ms/epoch - 377us/step
Epoch 4/20
469/469 - 0s - loss: 0.2912 - accuracy: 0.9189 - val_loss: 0.2788 - val_accuracy: 0.9226 - 192ms/epoch - 409us/step
Epoch 5/20
469/469 - 0s - loss: 0.2830 - accuracy: 0.9212 - val_loss: 0.2763 - val_accuracy: 0.9228 - 177ms/epoch - 378us/step
Epoch 6/20
469/469 - 0s - loss: 0.2771 - accuracy: 0.9226 - val_loss: 0.2744 - val_accuracy: 0.9236 - 177ms/epoch - 377us/step
Epoch 7/20
469/469 - 0s - loss: 0.2730 - accuracy: 0.9243 - val_loss: 0.2731 - val_accuracy: 0.9231 - 179ms/epoch - 381us/step
Epoch 8/20
469/469 - 0s - loss: 0.2696 - accuracy: 0.9255 - val_loss: 0.2712 - val_accuracy: 0.9251 - 179ms/epoch - 382us/step
Epoch 9/20
469/469 - 0s - loss: 0.2669 - accuracy: 0.9268 - val_loss: 0.2720 - val_accuracy: 0.9249 - 179ms/epoch - 381us/step
Epoch 10/20
469/469 - 0s - loss: 0.2649 - accuracy: 0.9272 - val_loss: 0.2676 - val_accuracy: 0.9254 - 177ms/epoch - 377us/step
Epoch 11/20
469/469 - 0s - loss: 0.2630 - accuracy: 0.9276 - val_loss: 0.2664 - val_accuracy: 0.9266 - 179ms/epoch - 381us/step
Epoch 12/20
469/469 - 0s - loss: 0.2611 - accuracy: 0.9287 - val_loss: 0.2669 - val_accuracy: 0.9262 - 180ms/epoch - 384us/step
Epoch 13/20
469/469 - 0s - loss: 0.2598 - accuracy: 0.9288 - val_loss: 0.2673 - val_accuracy: 0.9257 - 181ms/epoch - 385us/step
Epoch 14/20
469/469 - 0s - loss: 0.2583 - accuracy: 0.9296 - val_loss: 0.2650 - val_accuracy: 0.9268 - 180ms/epoch - 385us/step
Epoch 15/20
469/469 - 0s - loss: 0.2571 - accuracy: 0.9294 - val_loss: 0.2650 - val_accuracy: 0.9272 - 180ms/epoch - 384us/step
Epoch 16/20
469/469 - 0s - loss: 0.2564 - accuracy: 0.9302 - val_loss: 0.2669 - val_accuracy: 0.9270 - 178ms/epoch - 380us/step
Epoch 17/20
469/469 - 0s - loss: 0.2551 - accuracy: 0.9309 - val_loss: 0.2639 - val_accuracy: 0.9278 - 180ms/epoch - 383us/step
Epoch 18/20
469/469 - 0s - loss: 0.2542 - accuracy: 0.9308 - val_loss: 0.2644 - val_accuracy: 0.9275 - 181ms/epoch - 386us/step
Epoch 19/20
469/469 - 0s - loss: 0.2531 - accuracy: 0.9314 - val_loss: 0.2659 - val_accuracy: 0.9272 - 180ms/epoch - 384us/step
Epoch 20/20
469/469 - 0s - loss: 0.2526 - accuracy: 0.9313 - val_loss: 0.2651 - val_accuracy: 0.9270 - 177ms/epoch - 378us/stepplot(history, smooth = FALSE)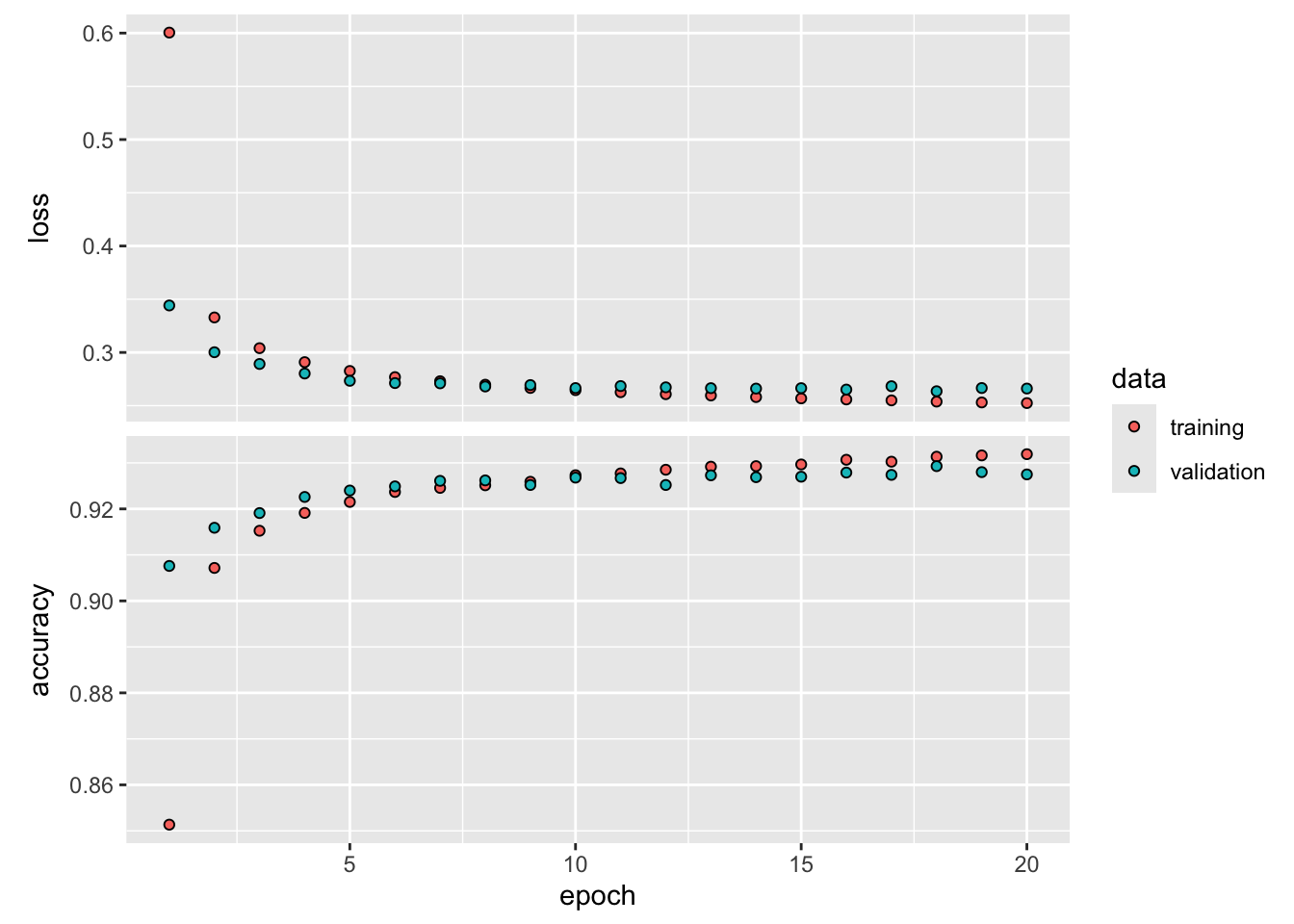
Even with just a single layer, the model performs quite well, its accuracy is around 93%. Adding the additional layer in the previous ANN did improve the accuracy. On the other hand, it took more than 100,000 extra parameters to move from 93% to 98% accuracy.