Principal component analysis (PCA) is one of the most important methods of unsupervised learning with many applications:
Summarization: summarize a \(p\)-dimensional matrix \(\textbf{X}_{(n\times p)}\) through a lower-dimensional matrix \(\textbf{Z}_{(n\times m)}\). \(m\) is usually much smaller than \(p\), and in many cases \(m=2\), especially if the results are to be presented graphically.
Visualization: Instead of all \({p\choose 2}\) two-way scatterplots between \(p\) variables, display a single scatterplot of the first two principal components.
Dimension reduction: Use the first \(m\) principal components as inputs to a regression model (see PCR, Section 8.3.2). Apply a clustering algorithm such as \(k\)-means clustering to the first \(m\) principal components.
Imputation: Use principal components iteratively to complete a numerical matrix that contains missing values.
Given the many applications it is no surprise that PCA is a key method in the toolbox of data scientists and machine learners. It goes back to 1901, when it was invented by Karl Pearson.
A principal component is a linear combination of the \(p\) inputs. The elements of the \(j\)th component score vector are calculated as follows: \[
z_{ij} = \psi_{1j} x_{i1} + \psi_{2j} x_{i2} + \cdots + \psi_{pj} x_{ip} \quad i=1,\cdots,n; j=1,\cdots,p
\] The coefficients \(\psi_{kj}\) are called the rotations or loadings of the principal components. In constructing the linear combination, the \(x\)s are always centered to have a mean of zero and are usually scaled to have standard deviation one. More on whether to scale the data for PCA follows below.
The scores \(z_{ij}\) are then collected into a score vector \(\textbf{z}_j = [z_{1j}, \cdots, z_{nj}]\) for the \(j\)th component. Note that for each observation \(i\) there are \(p\) inputs and \(p\) scores. So what have we gained? Instead of the \(p\) vectors \(\textbf{x}_1, \cdots, \textbf{x}_p\) we now have the \(p\) vectors \(\textbf{z}_1, \cdots, \textbf{z}_p\). Because of the way in which the \(\psi_{kj}\) are found, the PCA scores have very special properties:
They have zero mean (if the data was centered):\(\sum_{i=1}^n z_{ij} = 0\)
They are uncorrelated: \(\text{Corr}[z_j, z_k] = 0, \forall j \ne k\)
\(\text{Var}\left[\sum_{j=1}^p z_j\right] = \sum_{j=1}^p \text{Var}[z_j] = p\) (if data was scaled)
The components are ordered in terms of their variance \(\Rightarrow \text{Var}[z_1] > \text{Var}[z_2] > \cdots > \text{Var}[z_p]\)
This is useful in many ways:
The components provide a decomposition of the variability in the data. The first component explains the greatest proportion of the variability, the second component explains the next largest proportion of variability and so forth.
The contributions of the components are independent, each component is orthogonal to the other components. For example the second component is a linear combination of the \(X\)s that models a relationship not captured by the first (or any other) component.
The loadings for each component inform about the particular linear relationship. The magnitude of the loading coefficients reflects which inputs are driving the linear relationship. For example, when all coefficients are of similar magnitude, the component expresses some overall, average trend. When a few coefficients stand out it suggests that the associated attributes explain most of the variability captured by the component.
To summarize high-dimensional data, we can ignore those components that explain a small amount of variability and turn a high-dimensional problem into a lower-dimensional one. Often, only the first two principal components are used to visualize the data and for further analysis.
Principal versus Principle.
A principle refers to a fundamental law or rule, for example, “the principles of Christianity” or “the principle of judicial review”. You might agree with someone in principle, but disagree with their approach. A principal, on the other hand, refers to something head, chief, main, or leading. The principal of the school is the head of the school. They are leading the school. The principal reason for doing something is the main reason for doing it.
PCA is principal component analysis because the leading components are the main accountants of variability.
An alternative interpretation of the principal components is to find \(p\) vectors \(\textbf{z}_1,\cdots,\textbf{z}_p\) as linear combinations of the \(\textbf{x}_1,\cdots,\textbf{x}_p\) such that
\(\textbf{z}_1\) explains the most variability of the \(X\)s
\(\textbf{z}_2\) explains the second-most variability of the \(X\)s
… and so forth
and the \(\textbf{z}\) are orthogonal: \(\textbf{z}_j^\prime\textbf{z}_k = 0, \forall j,k\).
\(\textbf{z}_1\) is a projection of the \(X\)s in the direction that explains the most variability in the data.
\(\textbf{z}_2\) is a projection of the \(X\)s in the direction that explains the second-most variability in the data.
the \(\textbf{z}_j\) represent jointly perpendicular directions through the space of the original variables.
Viewing the components as projections into perpendicular directions hints at one technique for calculating the rotation matrix \(\boldsymbol{\Psi} = [\psi_{kj}]\) rotation and the variance decomposition: through a matrix factorization into eigenvalues and eigenvectors.
24.2 Eigenvalue Decomposition
The PCA can be computed with a singular value decomposition (SVD) of the matrix \(\textbf{X}\) or with an eigendecomposition of the covariance or correlation matrix of \(\textbf{X}\). The SVD is numerically more stable than the eigendecomposition, but we can demonstrate the computations easily using eigenvalues and eigenvectors.
The eigendecomposition of a square \(n \times n\) matrix \(\textbf{A}\) is \[
\textbf{A}= \textbf{Q}\boldsymbol{\Lambda}\textbf{Q}^{-1}
\] where \(\textbf{Q}\) is the \(n \times n\) matrix containing the eigenvectors of \(\textbf{A}\) and \(\boldsymbol{\Lambda}\) is a diagonal matrix with the eigenvalues of \(\textbf{A}\) on the diagonal. If \(\textbf{A}\) is symmetric, then \(\textbf{Q}\) is orthogonal and \(\textbf{Q}^{-1} = \textbf{Q}^\prime\). The eigendecomposition of a real symmetric matrix is thus
\[
\textbf{A}= \textbf{Q}\boldsymbol{\Lambda}\textbf{Q}^\prime
\] How can we interpret eigenvectors and eigenvalues? The \(n\times 1\) vector \(\textbf{q}\) is an eigenvector of \(\textbf{A}\), if it satisfies the linear equation \[
\textbf{A}\textbf{q} = \lambda\textbf{q}
\] for a scalar \(\lambda\). This scalar is called the eigenvalue corresponding to \(\textbf{q}\). There are \(n\) eigenvectors and when they are arranged as the columns of a matrix you get \(\textbf{Q}\).
In R you can obtain the eigenvectors and eigenvalues of a square matrix with the eigen function. Principal components can be computed with the prcomp or the princomp functions, both included in the base stats package. prcomp uses the singular-value decomposition of \(\textbf{X}\), princomp relies on the eigendecomposition of the covariance matrix.
The princomp function in R has a fix_sign= option that controls the sign of the first loading coefficient to be positive. Further discussion on loading coefficient signs can be found at the end of Section 24.6.
The following data were used to illustrate PCA scores in Section 8.3.2.
The eigen function returns the diagonal elements of \(\boldsymbol{\Lambda}\) in e$values and the matrix \(\textbf{Q}\) of eigenvectors in e$vectors. The input matrix of the decomposition can be reconstructed from those:
A <- e$vectors %*%diag(e$values) %*%t(e$vectors)round((c - A),4)
What happens if we multiply the \(10 \times 4\) data matrix with the \(4\times 4\) matrix of eigenvectors of the correlation matrix? First, we center and scale the data. The result is a \(10 \times 4\) matrix of linear transformations. These are the scores of the PCA.
In Python you can obtain the eigenvectors and eigenvalues of a square matrix with the linalg.eig function. Principal components can be computed with the PCA function, included in the sklearn package. PCA uses the singular-value decomposition of \(\textbf{X}\).
The following data were used to illustrate PCA scores in Section 8.3.2.
import pandas as pdimport numpy as np# Create the data frame data = pd.DataFrame({'x1': [0.344167, 0.363478, 0.196364, 0.2, 0.226957,0.204348, 0.196522, 0.165, 0.138333, 0.150833],'x2': [0.363625, 0.353739, 0.189405, 0.212122, 0.22927,0.233209, 0.208839, 0.162254, 0.116175, 0.150888],'x3': [0.805833, 0.696087, 0.437273, 0.590435, 0.436957,0.518261, 0.498696, 0.535833, 0.434167, 0.482917],'x4': [0.160446, 0.248539, 0.248309, 0.160296, 0.1869,0.0895652, 0.168726, 0.266804, 0.36195, 0.223267]})print(data)
The linalg.eig function returns the diagonal elements of \(\boldsymbol{\Lambda}\) in eigenvalues and the matrix \(\textbf{Q}\) of eigenvectors in eigenvectors. The input matrix of the decomposition can be reconstructed from those:
A = eigenvectors @ np.diag(eigenvalues) @ eigenvectors.Tprint(np.round(c - A, 4))
What happens if we multiply the \(10 \times 4\) data matrix with the \(4\times 4\) matrix of eigenvectors of the correlation matrix? First, we center and scale the data. The result is a \(10 \times 4\) matrix of linear transformations. These are the scores of the PCA.
from sklearn.preprocessing import StandardScalerimport mathfrom sklearn.preprocessing import scale # Standardize the data scaler = StandardScaler()data_c = scaler.fit_transform(data)data_c = pd.DataFrame(data_c, columns=data.columns)#Function to correct standard deviation calculation from n dof to n-1 dofdef sd_correct(x, n): correction = x * math.sqrt(n-1) / math.sqrt(n)return correction#Correcting to n-1 degrees of freedomdata_c = data_c.map(lambda x: sd_correct(x, n=10))# Calculate PCA scores scores = data_c @ eigenvectorsscores = pd.DataFrame(scores)print(scores)
We prefer the prcomp function to compute the PCA over the princomp function because it is based on the singular value decomposition, which is numerically more stable than the eigendecomposition. (Singular values are the square roots of the eigenvalues and since eigenvalues can be very close to zero working with square roots stabilizes the calculations.)
By default, prcomp centers the data but does not scale it. Add scale.=TRUE to scale the data as well.
prcomp reports the standard deviations (pca$dev) and rotation matrix \(\boldsymbol{\Psi}\) (pca$rotation). You will recognize the rotation as the matrix of eigenvectors from the previous analysis and the standard deviations as the square roots of the variances of the scores computed earlier. When retx=TRUE is specified, the function returns the PCA scores in pca$x.
The sum of the variances of the principal components is \(p=4\) and it can be used to break down the variance into proportions explained by the components.
summary(pca)
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.7196 0.9186 0.44555 0.02424
Proportion of Variance 0.7393 0.2109 0.04963 0.00015
Cumulative Proportion 0.7393 0.9502 0.99985 1.00000
from sklearn.decomposition import PCA# Using sklearn's PCA (equivalent to R's prcomp)pca = PCA(n_components=4)pca_scores = pca.fit_transform(data_c)
Component Loadings:
print(pd.DataFrame(pca.components_.T, columns=[f'PC{i+1}'for i inrange(4)], index=data.columns))
PCA reports the explained variances (pca.explained_variance_). The standard deviations can be calculated by taking the square root of the explained variances. To obtain the rotation matrix \(\boldsymbol{\Psi}\) transpose the component output (pca.components_.T). You will recognize the rotation as the matrix of eigenvectors from the previous analysis and the standard deviations as the square roots of the variances of the scores computed earlier. PCA scores can be found with pca.fit_transform().
The sum of the variances of the principal components is \(p=4\) and it can be used to break down the variance into proportions explained by the components.
# Function for Table of Standard Deviation and Explained Variances by PCdef PCA_sum(pca): var_sum = pd.DataFrame(np.array((pca.explained_variance_ , pca.explained_variance_ratio_, np.cumsum(pca.explained_variance_ratio_))))#Change explained variance to standard deviation by taking square root var_sum.iloc[0] = var_sum.iloc[0].apply(lambda x: math.sqrt(x)) colnames = [f'PC{i+1}'for i inrange(pca.n_components)] var_sum = var_sum.set_axis(colnames, axis=1) var_sum.index = ['Standard Deviation', 'Explained Variance Ratio', 'Cumulative Explained Variance Ratio']return var_sumPCA_sum(pca)
PC1 PC2 PC3 PC4
Standard Deviation 1.719617 0.918597 0.445545 0.024239
Explained Variance Ratio 0.739271 0.210955 0.049628 0.000147
Cumulative Explained Variance Ratio 0.739271 0.950225 0.999853 1.000000
The first principal component, with somewhat equal loading coefficients for \(X_1\), \(X_2\), and \(X_3\), explains 73.927% of the overall variance. The second component, which is dominated by \(X_4\), explains an additional 21.095% of the variance.
24.4 Predicting in a PCA
You can predict a new observation using principal components by calculating the component scores for the new obs. For example, suppose the input values for the new data point are the square roots of the values for the first observation:
xx = np.sqrt(data.iloc[0]) # the "new" observation# Using sklearn's transform methodxx_reshaped = xx.values.reshape(1, -1) # reshape for sklearnnewdata = pd.DataFrame(scaler.transform(xx_reshaped)).map(lambda x: sd_correct(x, n=10))pca_prediction = pca.transform(newdata)print(pca_prediction[0])
[ 6.20219314 -4.36281244 1.5534247 -0.54249853]
The predicted value is a vector, with one element for each of the components. To reconstruct the predicted value, we can apply the rotation matrix to the new observation. Before doing so, the values need to be centered and scaled to match the derivation of the rotations. It is thus important to apply the same centering and scaling values that were used on the training data:
# Manually scaling new observation with with original training and scaling valuesxx_centered_and_scaled = pd.DataFrame((xx_reshaped - scaler.mean_) / scaler.scale_).map (lambda x: sd_correct(x, n=10)) # Manual calculation of predictions by matrix multiplication of scaled and centered# data and rotation matrixmanual_pred = xx_centered_and_scaled @ pca.components_.Tcolnames = [f'PC{i+1}'for i inrange(pca.n_components)]manual_pred = manual_pred.set_axis(colnames, axis=1)print(manual_pred)
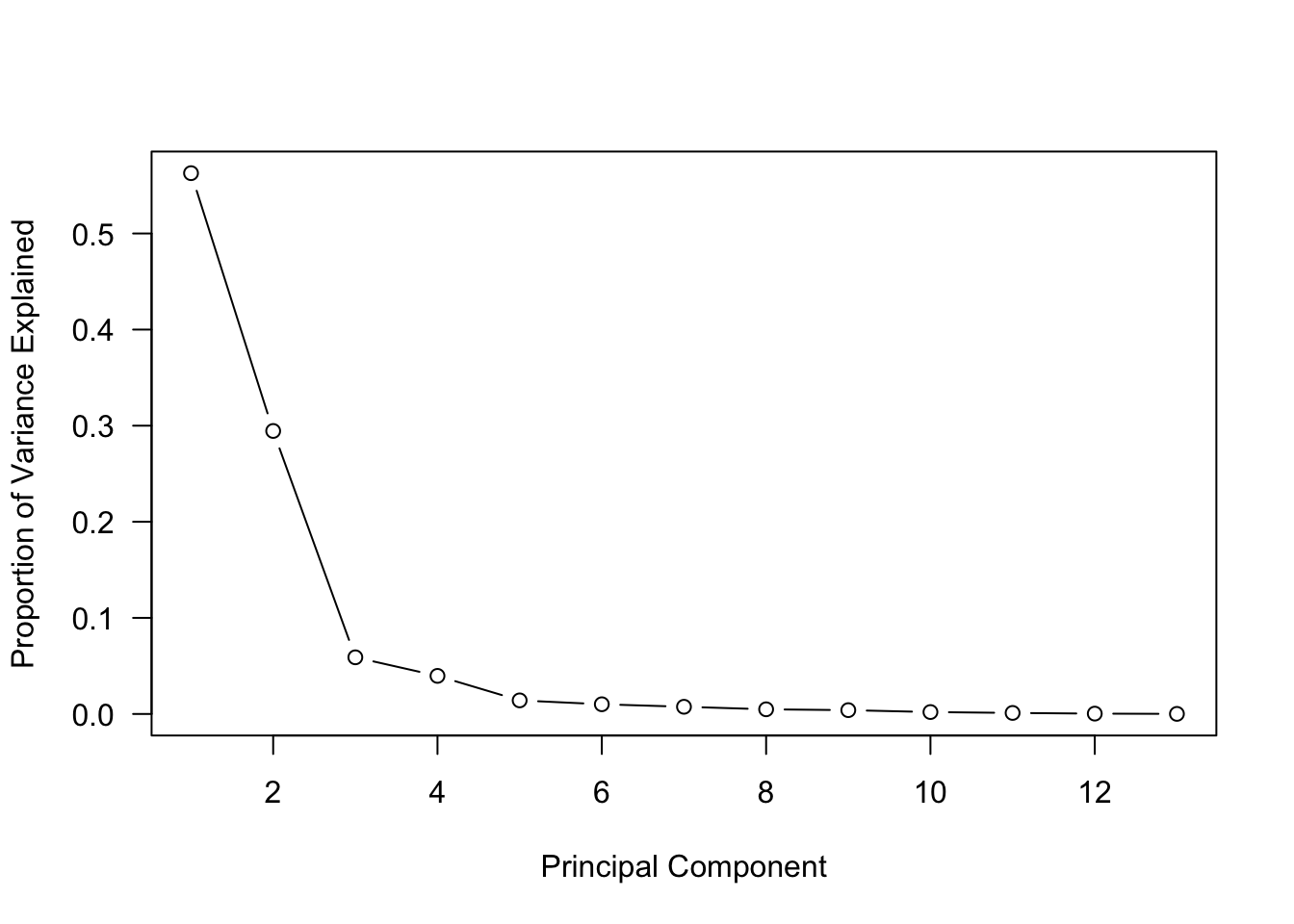
How should we choose the number of principal components to use in subsequent analyses? If the goal is summarization or visualization \(m=2\) is common. If the components are input to a regression model, cross-validation can be used in PCR (Section 8.3.2). In other situations you have to choose \(m\) such that a “fair” amount of variation is explained. To help with that, a scree plot is commonly used. Scree describes the small rock material that accumulates at the base of a mountain or steep rock formation (Figure 24.1). The scree forms a sharp transition from the rocky cliff to the area of the rock fragments.
Figure 24.1: Scree at the base of a mountain. Source: Wikipedia
In principal component analysis the scree plot displays the proprtion of variance explained against the number of components.
Example: Hitters Data (ISLR2)
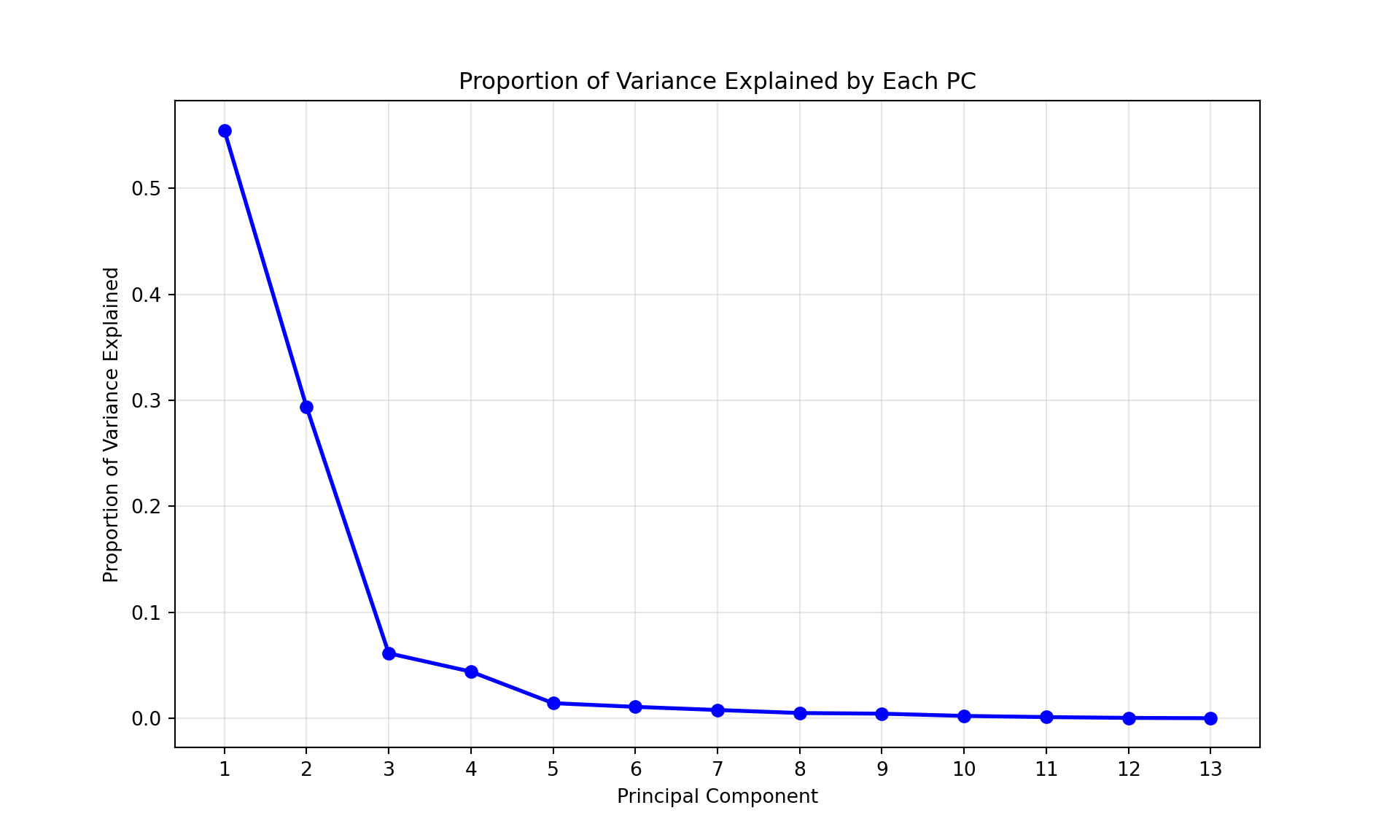
For the Hitters baseball data set from James et al. (2021), the PCA scree plot is obtained as follows:
import matplotlib.pyplot as pltplt.figure(figsize=(10, 6))plt.plot(range(1, 14), pca_hit.explained_variance_ratio_, 'b-o', linewidth=2, markersize=6)plt.xlabel('Principal Component')plt.ylabel('Proportion of Variance Explained')plt.title('Proportion of Variance Explained by Each PC')plt.grid(True, alpha=0.3)plt.xticks(range(1, 14))
([<matplotlib.axis.XTick object at 0x337a7e780>, <matplotlib.axis.XTick object at 0x3375a2fc0>, <matplotlib.axis.XTick object at 0x337aa6360>, <matplotlib.axis.XTick object at 0x337ae0590>, <matplotlib.axis.XTick object at 0x337aa6660>, <matplotlib.axis.XTick object at 0x337a892e0>, <matplotlib.axis.XTick object at 0x337ae2cf0>, <matplotlib.axis.XTick object at 0x337ae3bc0>, <matplotlib.axis.XTick object at 0x337b78680>, <matplotlib.axis.XTick object at 0x337ae21e0>, <matplotlib.axis.XTick object at 0x337b79220>, <matplotlib.axis.XTick object at 0x337b79a30>, <matplotlib.axis.XTick object at 0x337b7a600>], [Text(1, 0, '1'), Text(2, 0, '2'), Text(3, 0, '3'), Text(4, 0, '4'), Text(5, 0, '5'), Text(6, 0, '6'), Text(7, 0, '7'), Text(8, 0, '8'), Text(9, 0, '9'), Text(10, 0, '10'), Text(11, 0, '11'), Text(12, 0, '12'), Text(13, 0, '13')])
plt.show()
The sharp “knee” (“elbow”) at \(m=3\) shows that most of the variability is captured by the first two principal components.
24.6 Biplot
The biplot of a PCA displays the scores and loadings for two principal components in the same visualization. Typically, it is produced using the first two components as these account for the most variability. The scores \(z_{ij}\) are shown in the biplot as a scatter, the rotations are displayed as arrows. Points that are close to each other on the biplot have similar values of the inputs. The length of an arrow depicts the contribution of the variable, long arrows correspond to large coefficients in the rotation matrix. The angle of the arrows shows the correlation with other variables:
uncorrelated variables have perpendicular arrows
highly correlated variables have arrows that point in the same direction
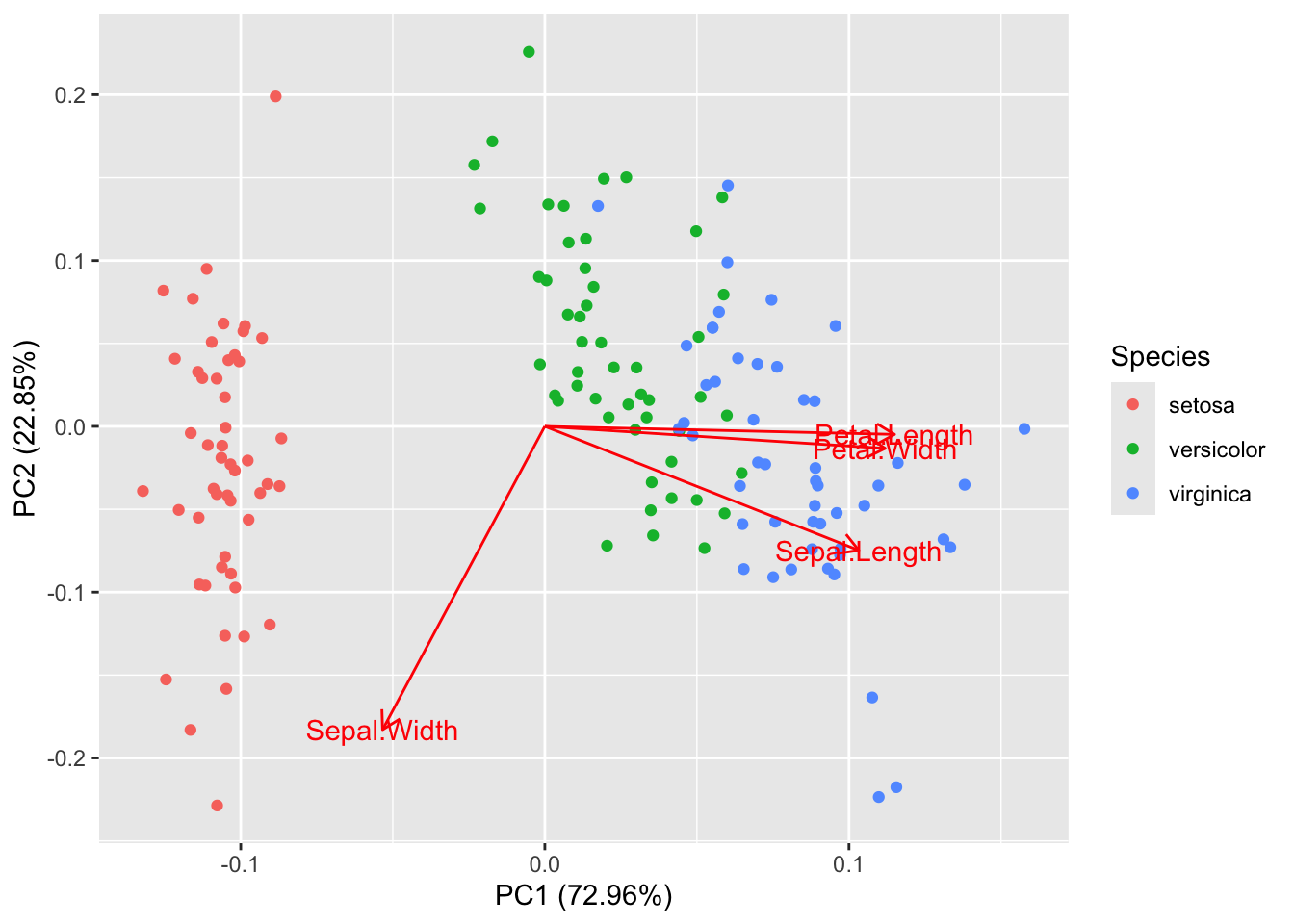
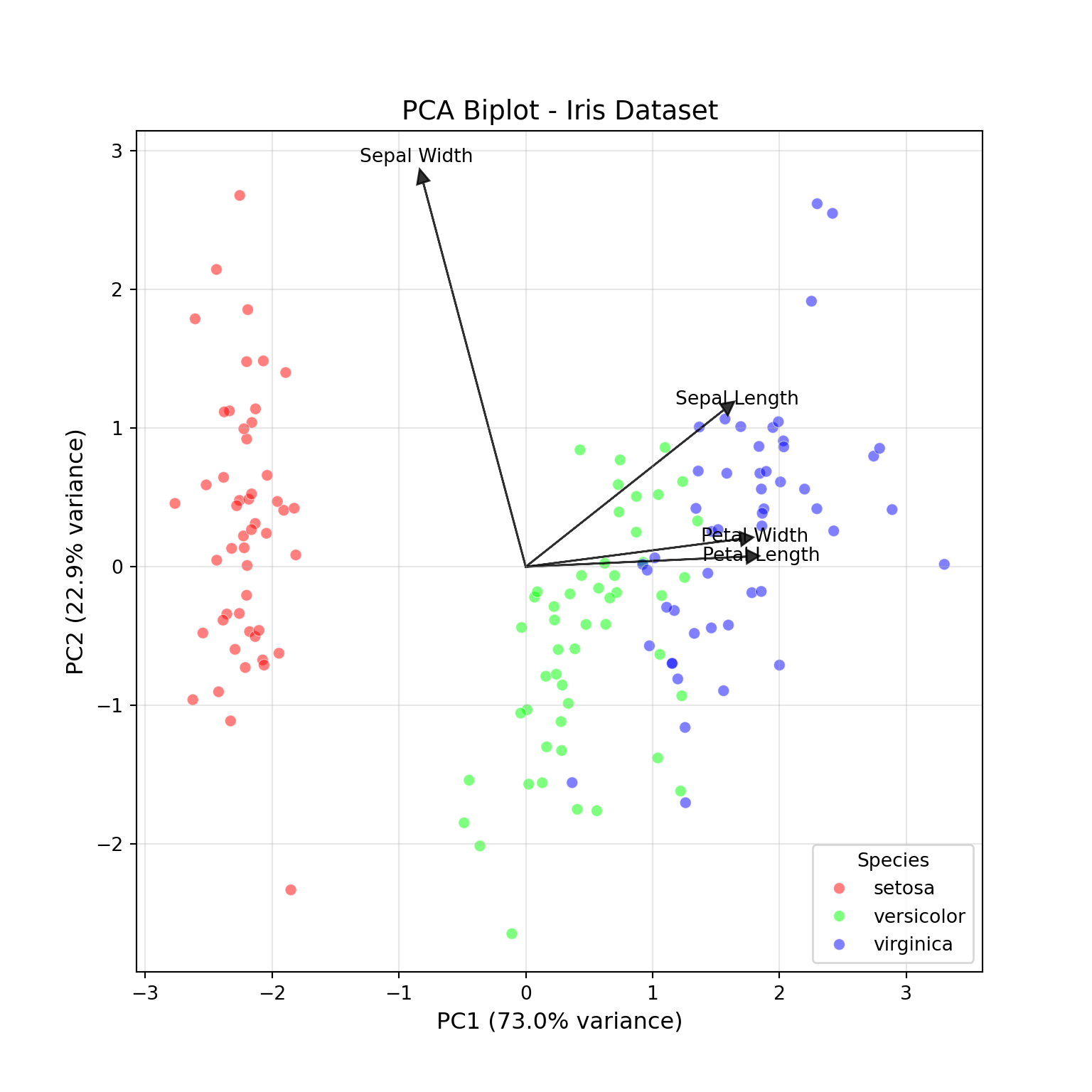
Example: PCA for Iris Data
For the Iris data, the first two principal component account for 95% of the variability in the four flower measurements.
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.7084 0.9560 0.38309 0.14393
Proportion of Variance 0.7296 0.2285 0.03669 0.00518
Cumulative Proportion 0.7296 0.9581 0.99482 1.00000
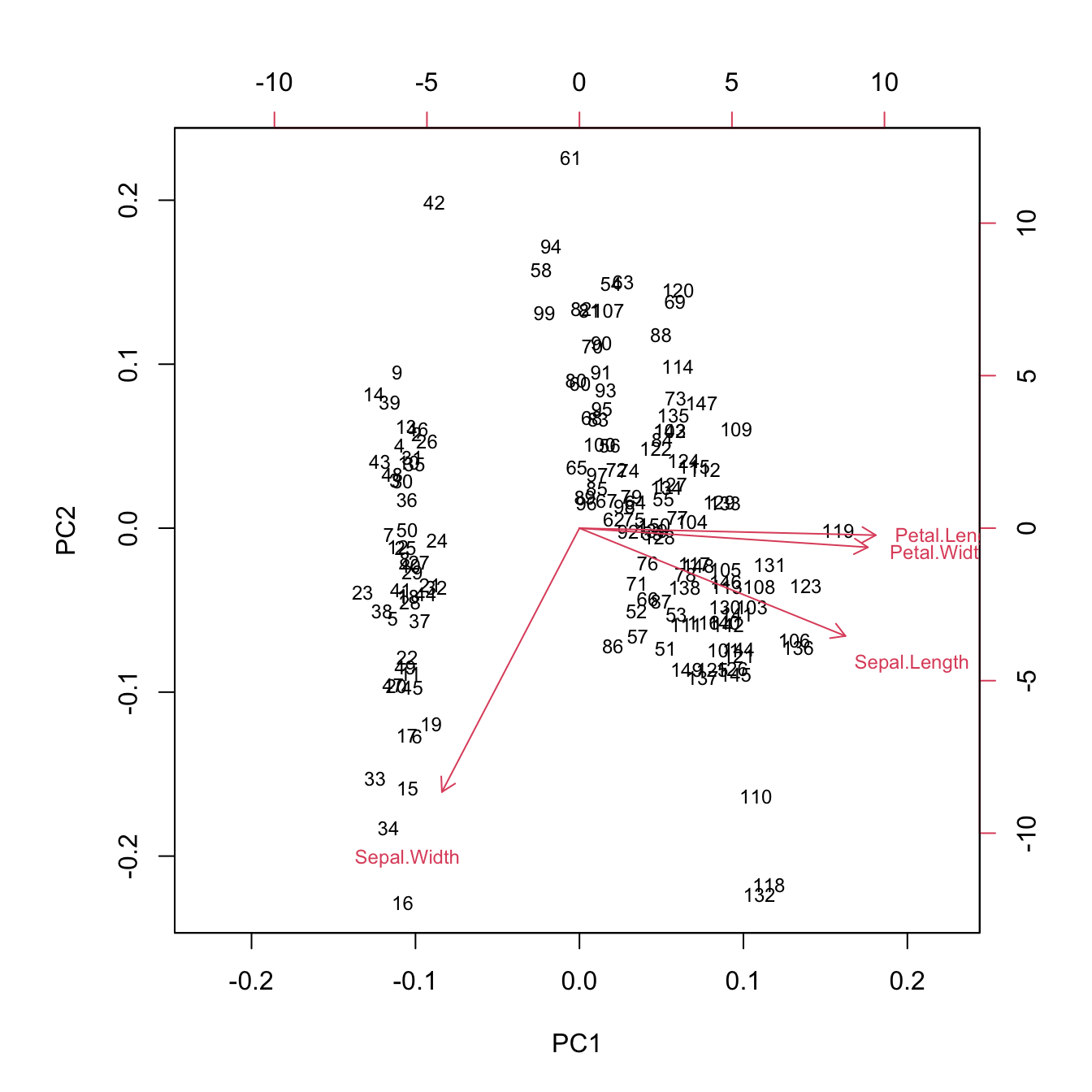
The raw data for the biplot (Figure 24.2) of the first two components are the first two columns of the rotation matrix and the first two columns of the score matrix:
Figure 24.2: Biplot for first two principal components of Iris data.
There are two systems of axes on the biplot. The axes on the bottom and on the left are for the scores of the principal components. The axes on the right and on the top are for the variable arrows (the rotations). Note that the Sepal.Width rotation for the first two components is [-0.2693474, -0.9232957] but the arrow does not point at that coordinate. The biplot function applies a scaling to the scores and the arrows, which you can suppress by adding scale=0 to the function call.
# Table of Standard Deviation and Explained VariancesPCA_sum(pca_iris)
PC1 PC2 PC3 PC4
Standard Deviation 1.708361 0.956049 0.383089 0.143926
Explained Variance Ratio 0.729624 0.228508 0.036689 0.005179
Cumulative Explained Variance Ratio 0.729624 0.958132 0.994821 1.000000
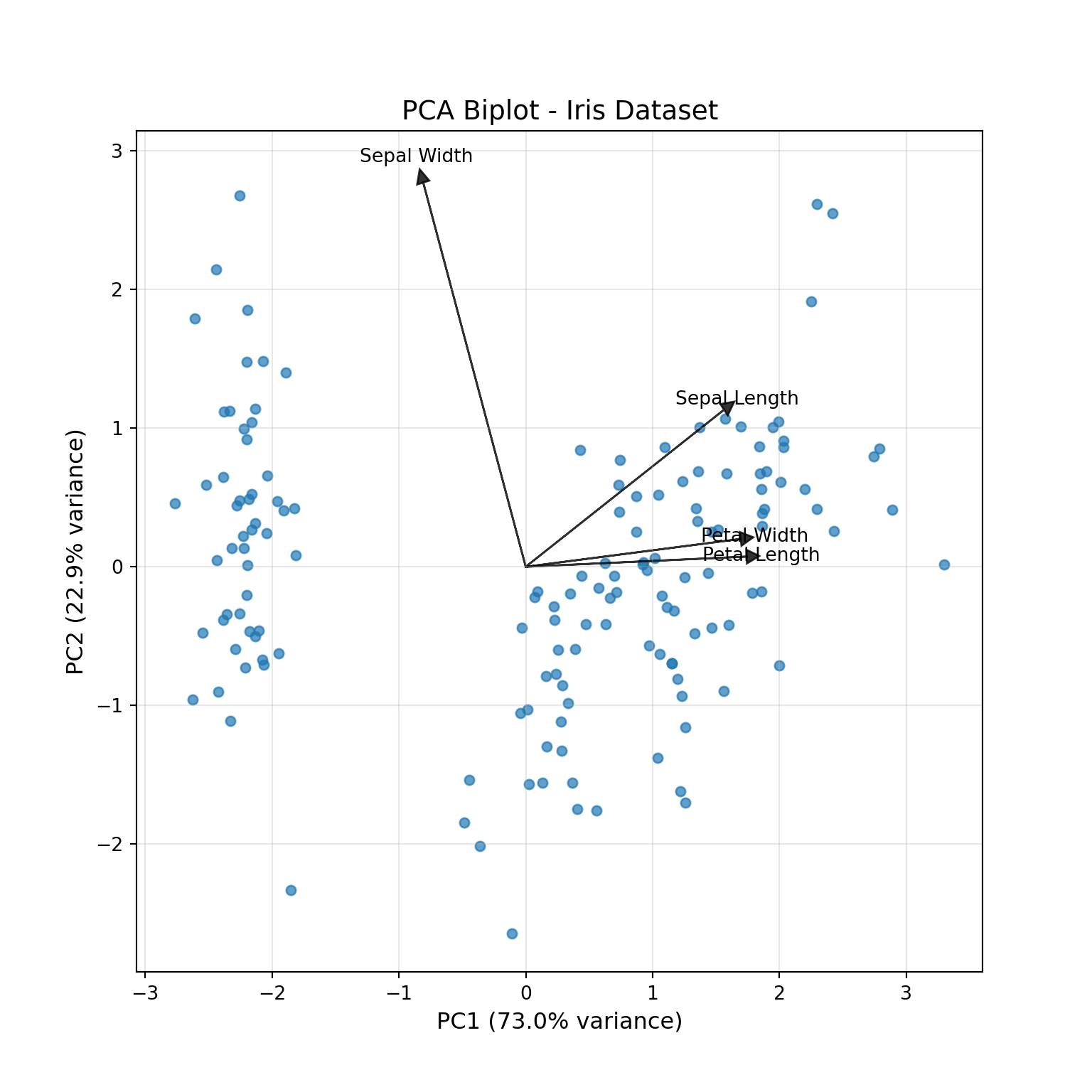
The raw data for the biplot (Figure 24.3) of the first two components are the first two columns of the rotation matrix and the first two columns of the score matrix:
Figure 24.3: Biplot for first two principal components of Iris data.
We see from the biplot that the scores cluster in distinct groups. The arrow for Sepal.Width is pointing away from the arrows of the other variables, which suggests that it is not highly correlated with the other flower measurements. The length and width of the petals are very highly correlated, however; their arrows point into nearly the same direction. This can be verified by computing the correlation matrix of the measurements:
Using the autoplot function in the ggfortify library allows you to color the scores in the biplot by another variable. We see that the distinct group of scores low in PC1 correspond to the Iris setosa species.
The following plot colors the scores in the biplot by species. We see that the distinct group of scores low in PC1 correspond to the Iris setosa species.
I. setosa has large sepal widths and the negative rotation coefficient for Sepal.Width in PC1 separates the species in that dimension from the other species.
Sepal.Width
min max mean
Species
setosa 2.3 4.4 3.43
versicolor 2.0 3.4 2.77
virginica 2.2 3.8 2.97
Looking at the sign of the rotation coefficients is helpful to determine which input variables increase or decrease a component compared to other inputs. However, you cannot interpret the sign as increasing or decreasing a target variable. The rotation matrix of a principal component analysis is unique up to sign. Two software packages might produce the same rotation matrices, but with different signs of the coefficients.
24.7 To Scale or Not To Scale
The variables should always be centered to have mean 0, so that the loadings have the same origin. Should the variables also be scaled to have the same variance?
In general, scaling is recommended whenever the results of an analysis depends on units of measurements. For example, when calculating distances it matters whether time is measured in days, hours, minutes, or seconds. The choice of units should not affect the outcome of the analysis. Similarly, large things tend to have greater variability than small things. Since the principal components are arranged in the order of variability explained, variables that have very large variances (because of their units of measurement or size) will dominate the components unless scaling is applied.
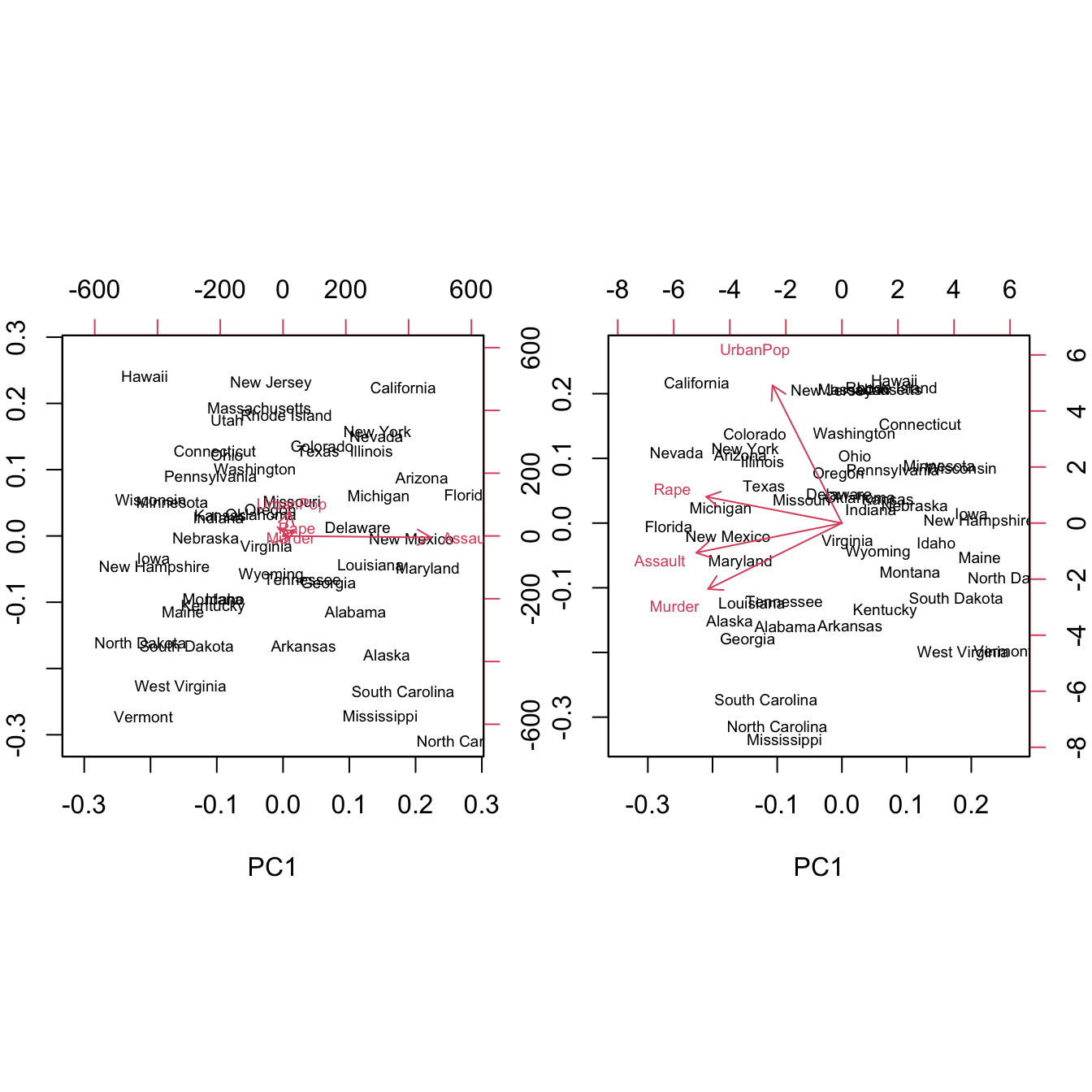
Example: U.S. Arrests
The USArrests data set contains statistics, in arrests per 100,000 residents for assault, murder, and rape in each of the 50 U.S. states in 1973. Also given is the percent of the population living in urban areas.
#Import data from duckdbcon = duckdb.connect(database="ads.ddb", read_only=True)USArrests = con.sql("SELECT * FROM USArrests;").df()con.close()USArrests.head()
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 83.7324 14.21240 6.4894 2.48279
Proportion of Variance 0.9655 0.02782 0.0058 0.00085
Cumulative Proportion 0.9655 0.99335 0.9991 1.00000
# PCA without scalingpca_unscaled = PCA(n_components=4)pca_unscaled_transformed = pca_unscaled.fit_transform(USArrests)#Rotation Matrix# Set column names for each principal componentcolnames = [f'PC{i+1}'for i inrange(4)]pca_unscaled_rotation = pd.DataFrame(pca_unscaled.components_.T, columns = colnames, index = USArrests.columns[:4])pca_unscaled_rotation
PC1 PC2 PC3 PC4
Standard Deviation 83.732400 14.212402 6.489426 2.482790
Explained Variance Ratio 0.965534 0.027817 0.005800 0.000849
Cumulative Explained Variance Ratio 0.965534 0.993352 0.999151 1.000000
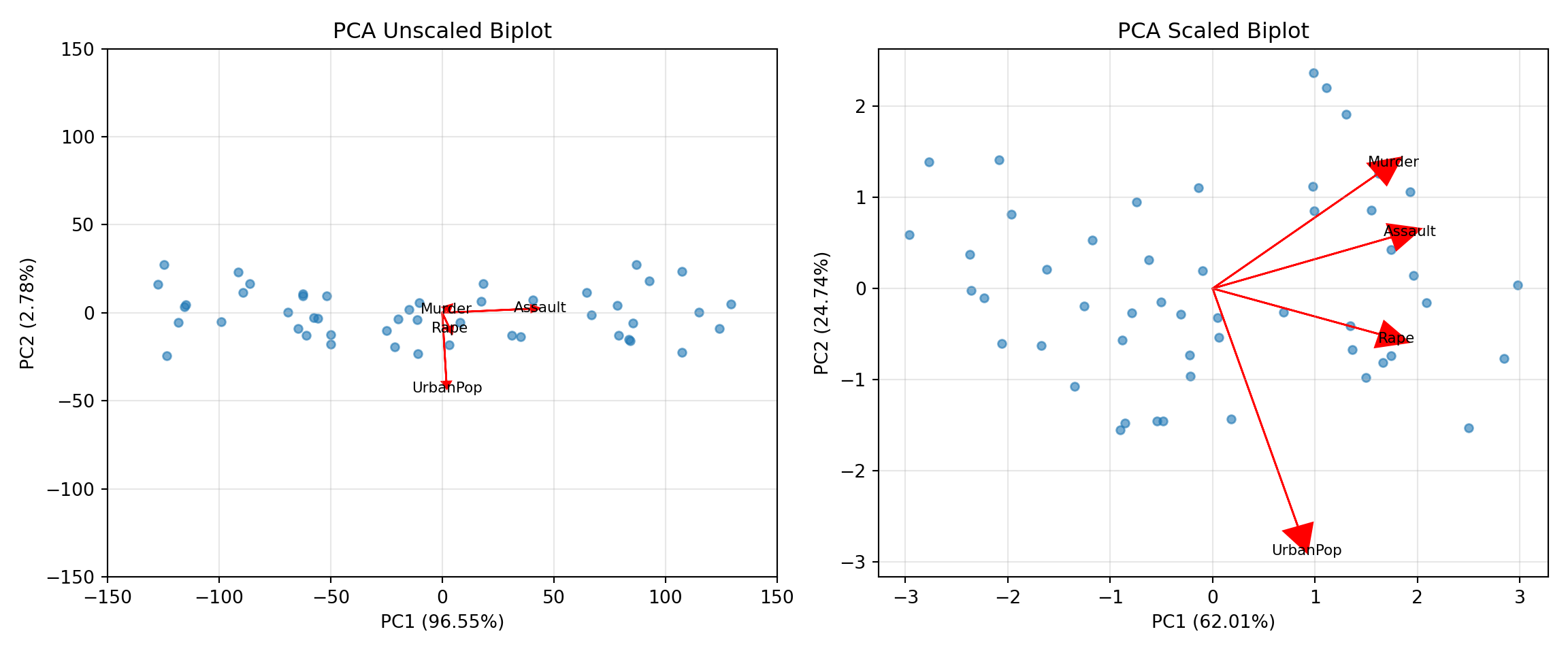
The first principal component in the unscaled analysis explains 96.55% of the variability. The component is dominated by the Assault variable, with a loading coefficient of 0.9952.
PC1 PC2 PC3 PC4
Standard Deviation 1.574878 0.994869 0.597129 0.416449
Explained Variance Ratio 0.620060 0.247441 0.089141 0.043358
Cumulative Explained Variance Ratio 0.620060 0.867502 0.956642 1.000000
In the scaled analysis the variables are on equal footing with respect to their dispersion. The loading coefficients are more evenly sized in the first principal component which explains 62.01% of variability in the scaled analysis. The Assault variable is not allowed to dominate the component analysis because of its large variance compared to the other variables.
The biplots for the scaled and unscaled analysis are markedly different. The dominance of Assault in the unscaled analysis makes it difficult (impossible) to meaningfully interpret the biplot (Figure 24.4).
Figure 24.4: Biplots in unscaled (left) and scaled (right) analysis.
The biplots for the scaled and unscaled analysis are markedly different. The dominance of Assault in the unscaled analysis makes it difficult (impossible) to meaningfully interpret the biplot (Figure 24.5).
Figure 24.5: Biplots in unscaled (left) and scaled (right) analysis.
In the next section we encounter a situation where we center but do not scale the \(\textbf{X}\) matrix, when values of the inputs are reconstructed.
24.8 Imputation through Matrix Completion
In the introduction to this chapter we expressed the PCA scores as a linear function of the inputs: \[
z_{ij} = \psi_{1j} x_{i1} + \psi_{2j} x_{i2} + \cdots + \psi_{pj} x_{ip} = \sum_{k=1}^p \psi_{kj}x_{ik}
\]
This relationship can be reversed, expressing the inputs as a linear combination of the PCA scores and the rotations: \[
x_{ij} = \sum_{k=1}^p z_{ik}\psi_{kj}
\]
To demonstrate, we can reconstruct the values for the first observation for the Iris data set from its PCA results. First, we only center the data and do not scale:
If only a subset of the principal components is used, we obtain an approximation of the input value. If \(M < p\), then
\[
x^*_{ij} = \sum_{k=1}^M z_{ik}\psi_{kj} \approx x_{ij}
\] In fact, \(x^*_{ij}\) is the best \(M\)-dimensional approximation to \(x_{ij}\) in terms of having the smallest Euclidean distance.
The sepal width of the first observation can be approximated based on the first two principal components as
If principal component analysis can be used to approximate the observed input values, then it can be used to predict unobserved values. This is the idea behind using PCA to impute missing values, a technique known as matrix completion. The advantage of using PCA to fill in missing values in matrices is to draw on the correlations between the variables, as compared to imputing missing values by column means, which ignores information from other variables.
It is important to point out, however, that this form of imputation is only appropriate if the missingness process is missing completely at random (MCAR): the missingness is unrelated to any study variable, including the target variable. For example, if a measurement cannot be taken because an instrument randomly stopped functioning, the missing value occurred completely at random. If the measurement cannot be taken because the instrument cannot record objects of that size, then the process is not MCAR.
An iterative algorithm for matrix completion is described in $12.3 of James et al. (2021) and implemented in the eimpute library in R. The algorithm starts with imputing missing values with the means of the observed data and iterates the following steps:
Perform a low-rank PCA, that is, a PCA with \(M < p\).
Replace the unobserved values with approximations based on the PCA scores and rotation.
Compute the mean squared error between observed \(x_{ij}\) and predicted \(x^*_{ij}\). As long as the mean squared error continues to decrease, return to step 1.
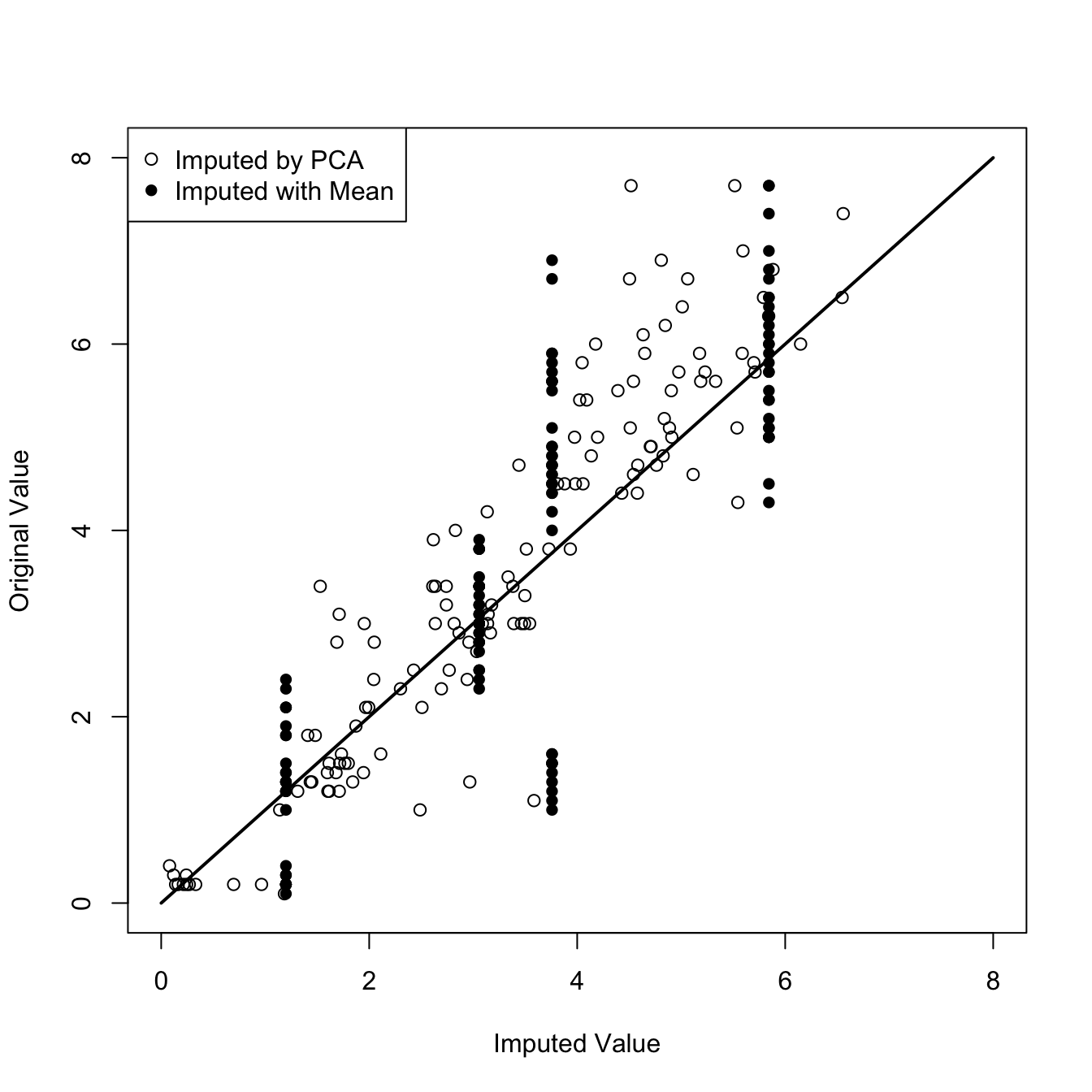
Figure 24.6 displays observed and imputed values for the Iris data set when 20% of the observations are randomly set to missing (by assigning NA). Two methods of imputation are used: using the column means, and a low-rank PCA approximation with 2 principal components using eimpute(x=iris_miss,r=2).
There are only four possible imputed values when using the column means, all missing values for a particular variable are replaced with the same column mean. The PCA imputation produces much more variety in the imputed values since it draws on the correlations between the variables.
Because missing values were introduced artificially, we have access to the true values and can compute the correlation between original and imputed values. This correlation is 0.83 for the imputation based on column means and 0.93 for the imputation based on the PCA.
Figure 24.6: Comparison of original and imputed values for Iris data with 20% missingness.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in r, 2nd Ed. Springer. https://www.statlearning.com/.