4 Data Science Teams
Group culture is one of the most powerful forces on the planet.
Not finance. Not strategy. Not technology. It is teamwork that
remains the ultimate competitive advantage, because it is so
powerful and so rare.
4.1 Upside Down, How Not to Build a Team
Before we discus roles on data science teams and whether centralized or decentralized teams are best for an organization, consider this story how a data science team comes to be, as told by Claire Sullivan in this Data Umbrella video.
Here are the Cliffs notes:
The CEO hears about data as the new oil, the competitors all create data strategies, data science teams, and have a Chief Data Officer. The CEO develops a serious case of FOMO (fear of missing out). Worried about remaining competitive, the CEO directs his people to “hire me some data scientists”. The HR department has no experience in hiring data scientists since the company does not have any yet. They do some background work, maybe engage a recruiting company, and hire a bunch of data scientist.
The data scientists start but there is no data culture in the company yet. There are no projects for them to work on, no product managers to guide any data product development. Since these are creative people, the data scientists look around and figure out what projects to work on. However, IT does not give them access to the data because the projects they invented are not tied to a business need. IT hands the data science team some Excel spreadsheets to make them go away—sigh. Since these are creative people, the data scientists start pulling some data together, building on their own some sub-optimal data pipeline that should have been built under normal circumstances by a data engineer.
Finally armed with some data, the data scientists engage in what they do best, building models. Once they have results they are anxious to show them to the mover and shakers in the company but have a hard time getting on people’s calendars; they are lacking a champion. Meanwhile, the CEO is getting impatient and is wondering where the return on investment (ROI) is in his data science initiative. Frustrated by lack of growth prospects at the company, lack of support, lack of mentoring, and lack of meaningful projects, the data scientists start leaving the company.
This is not an isolated story. It continues to play out in many companies and it contributes to the high turnover among data scientists. According to a study by online training company 365 Data Science Ltd., analyzing LinkedIn profiles, data scientists stay in their role a mere 1.7 years. Only 2% of the surveyed data scientists had been in their jobs for more than 5 years. Ugh.
What went wrong in the fable told in Clair Sullivan’s video?
- There was no business problem that could only be solved with data.
- Without a defined business problem there are no requirements for skill sets to be hired.
- Hiring was not done in an effective sequence: you might need data engineers before bringing data scientists on board.
- No data governance, the IT department did not know how to deal with a request for data from the data science team.
- Siloed data beyond the appropriate data governance structure reveals an absence of data culture.
- The data scientists created a solution without interfacing it with the business.
Starting by focusing on hiring people without first figuring out what they will do once they are on the job, not having a clue about what data you have and need and which problems can be solved with it, is the upside-down model of running data initiatives. It will likely fail.
The better way to start is to identify a problem (business problem, research question, policy issue) that can be solved by data. A problem that can only be solved by data is the best candidate, but there may be existing solutions and processes for which a data-based approach or a data-assisted approach is viable. It is a common question in organizations: “can we improve on what we already do by using (more of) the data we already have?”
A problem that can be solved by data does not necessarily require a data science team with data engineers, ML engineers, and architects. Maybe it just calls for replacing a bunch of Excel spreadsheets into a data pipeline that feeds a dashboard. You cannot properly staff a team if you do not know which tasks need to be accomplished. So let’s look at some common roles on data science teams.
4.2 Roles on Teams
In the beginning there was the unicorn data scientist, the lone wolf who had to know and do everything, master of all tasks. Things have changed and the roles on data science teams today are more differentiated. In building, leading, and working on data science teams you should be thinking about the tasks first and then which role will perform the tasks.
On small teams, the tasks are not done by different people, in larger organizations you will have more differentiated roles with specific tasks assigned to specific roles. For those organizations, this also raises the question whether to choose a centralized, decentralized, or hybrid organizational structure for the data science team(s). More on that below.
Drawing on this and this blog by the Data Science Process Alliance, the following roles and tasks are typically associated with data science teams. The role titles are not used consistently. If you see a job announcement for Data Scientist, Data Analyst, Data Science Architect, and so forth, check the list of responsibilities to see which role the announcement has in mind.
Data Scientist
This is the key role on data science teams. Typical tasks and responsibilities of the data scientist include
- Finding and interpreting rich data sources.
- Applying the scientific method of asking a question, developing a hypothesis, and testing the hypothesis
- Designing experiments to test hypotheses and measure the effectiveness of solutions.
- Using statistical learning and machine learning to build models.
- Understanding the end-to-end process of data science project.
- Interacting with stakeholders throughout the data science project life cycle.
- Presenting and communicating data insight to technical and non-technical audiences.
- Collaborating with data engineers and data analysts to collect and preprocess data, and to build and maintain data pipelines.
Data Engineer
The data engineer is another key role in data science projects, making data accessible and available. Tasks and responsibilities of the data engineer include
- Designing, building, and maintaining data pipelines to move and transform data.
- Developing and maintaining the infrastructure required to support data science projects (ETL or ELT tools, data lakes, data integration).
- Ensuring quality, accuracy, and consistency of data.
- Working with data scientists to understand data requirements.
Data Analyst
A data analyst is responsible for collecting, processing, and performing statistical analyses on data. Compared to the data scientist, analysts tend to be more focused on reporting the current state (what happened) than on modeling and predicting (what will happen).
Data analysts do not have (need) the mathematical and statistical knowledge of the data scientist and do not need training in the scientific method. A data scientist can more easily perform the tasks of a data analyst then the other way around. Data scientists are expected to have more expert-level statistical programming abilities, deeper knowledge in developing algorithms, mathematics and statistics, and more academic training.
Typical responsibilities of the data analyst include
- Collecting and processing data to ensure accuracy, quality, and consistency (overlap with data engineer).
- Analyzing data to find patterns and trends.
- Supporting business decisions through data insights.
- Developing and maintain dashboards and reports.
- Collaborating with data scientists and data engineers.
Data Science Architect
The data science architect is a data architect who supports and maintains the data infrastructure for data science projects. It is not a data scientist who architects data solutions. The tasks and responsibilities of the data science architect thus resemble more those of the general data architect, but with a specialization on data science projects:
- Designing and overseeing the data infrastructure and architecture, including storage and access of data for data science projects.
- Creating data models and build data pipelines.
- Choosing appropriate tools and technologies for data management
- Collaborating with data scientists to translate their requirements into data architectures.
There is considerable overlap with the role of data engineer.
Data Science Developer
Like the data science architect is a data architect who supports data science initiatives, the data science developer is more like a software developer who supports data science applications. The data science developer codes data applications and is a key role in deploying data science models into production. In some organizations, this role is also called the machine learning engineer.
The data science developer integrates data science solutions but is keenly aware of the differences between developing data applications and software development.
Compared to the data scientist, a data science developer is weaker in statistics and mathematics but stronger in writing production code and in building and maintaining enterprise-grade production systems. Tasks and responsibilities include
- Designing, developing, and deploying scalable data science solutions.
- Developing and maintaining machine learning workflows.
- Implementing and monitoring solutions to track model performance.
- Collaborating with data scientists to build production applications from data science assets.
Product Manager
The product manager sets the vision for the product and defines the product requirements. Product managers collect requirements from the stakeholders (customers, business leaders) and is accountable for the deliverable to the organization. Tasks and responsibilities of the product manager include
- Developing and delivering data products that meet customer needs.
- Communicating product requirements and progress to project stakeholders.
- Developing and maintaining product roadmaps.
- Deciding which features and functionality to build, and in what order.
- Prioritizing and signing off on work items.
Project Manager
While the product manager is responsible for the deliverable of a team, the project manager is responsible for the project execution. The roles get often confused. The project manager is a coach, facilitator, obstacle remover, and cheerleader. Responsibilities and tasks include
- Developing and implementing data science project plans.
- Ensuring that projects are completed on time and within budget.
- Coordinating day-to-day tasks of the team (who does what when).
- Managing stakeholder expectations.
- Scoping and defining tasks for the team.
Other Roles
There are many other roles that are relevant to the data science team, although they might sit organizationally outside of the team.
Subject matter expert (SME)
Subject matter experts (domain experts) have deep knowledge about the project domain. Keeping SMEs close is critical to understand the problem context, the problem requirements, rules and regulations the project is subject to, and what is custom, expected, and acceptable in a specific domain. You would not want to develop a fraud model for debit transactions without an expert on banking and payments weighing in. Chances are the fraud model will not be actionable without their input.
The SME can tell whether a data science model makes sense from a practical viewpoint. They can explain data in context and ensure patterns found by the data scientist are interpreted correctly.
Team manager
The team manager supervises the members of the data science team and is responsible for the people management (human resources) and is accountable for the success of the team. Tasks and responsibilities include
- Leading the data science team.
- Directing and mentoring the team members.
- Managing team resources (personnel, equipment, tools, vendor)
- Reporting on the team’s performance
4.3 Organizational Structure
The question whether to operate data science team(s) as a centralized team—also known as a data science center of excellence (COE)—or as separate decentralized teams in the units of the organization, is irrelevant for small organizations with a single team or possibly a single data scientist. In larger organizations the question is relevant. As data science grows in importance in those places and more data related roles are hired, it matters how to structure the team.
Centralized (COE)
In the centralized structure all data roles are in one organization. Business units such as Sales, Marketing, Product, Human Resources, or Finance draw on the data professional in that COE (Figure 4.1).
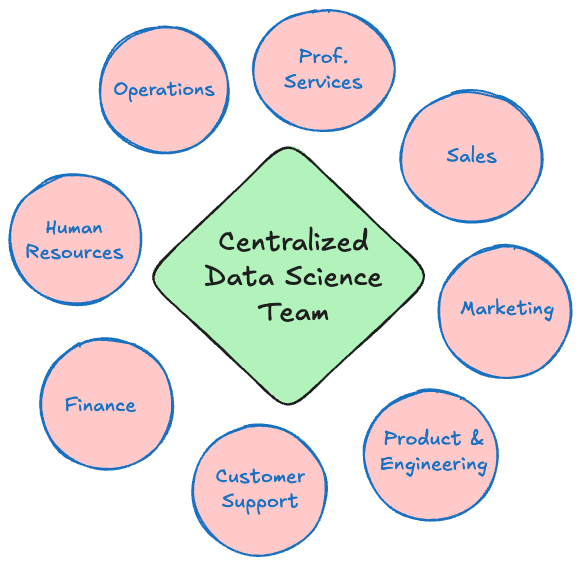
This structure has many advantages:
- Best practices. It is easier to establish and implement best practices in data governance, data management, model deployment, etc.
- Scale. Centralized teams are larger. There are benefits of having multiple employees in each role working together. This also helps with recruiting new talent. A larger unit tends to have more influence in the organization and representation at a higher executive level. COEs report to a Chief Data Scientist, Chief Data Officer, or Chief Analytics Officer. Although these tend not (yet) to be C-suite roles, they are more influential than a director-level position in a business unit (where decentralized teams report into).
- Systems and tools can be managed from one place. Negotiating vendor contracts is more efficient and results in better deals when one organization negotiates for larger contracts.
- Growth and advancement. COEs work on multiple projects across the entire organization. This gives exposure to different domains and enriches the data scientist experience. This opportunity for growth and learning can lead to promotions without having to change organizations.
A centralized structure is not without disadvantages:
- The data teams are removed from the business units where the domain knowledge (SMEs) resides.
- The centralized structure creates a wall between domain and data teams.
- The resources of a COE are not unlimited and every unit in the organization calls on them. It can be challenging to serve the needs of all units equitably.
- Units that have more data or that are closer to customers and revenue might get priority.
- Some business units are hesitant to provide access to sensitive data to employees outside of their control. Finance and Human Resources departments prefer to have their own employees work on finance or personnel data.
- The centralized structure, because of its size and central operation tends to be more bureaucratic and slower than a small agile team within a business unit.
Decentralized
In this organizational structure, Marketing, Sales, Finance, Human Resources, and so on, have their own data science teams. Advantages of this structure are data science teams that are aligned with the specific business unit and its domain (Figure 4.2).
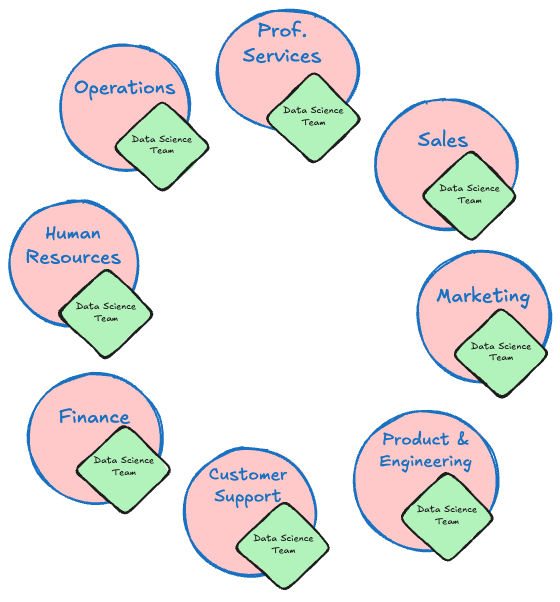
The Finance data science team knows how to work with finance data and what problems matter to the Finance organization. The data roles sit right next to the domain experts. The teams are smaller and more agile, able to respond to to requests more quickly. Prioritization is not much of a problem if a request comes from within the hierarchy.
The downside of multiple data science teams in different parts of the organization are also significant. Smaller teams do not have experts in all data roles. They either rely on IT to provide data engineering and developers or try and roll their own pipelines and solutions. The data science teams in a decentralized structure are similar to teams in small organizations. There is no overarching data science strategy across the organization and each team figures out its own best practices, tool chains, and processes. This leads to very fractured approaches, inconsistent environments, and duplication. The teams report into domain experts such as a Director of Marketing or a VP of Finance who do not have a data science background.
Hybrid
The advantages of the centralized structure are the disadvantages of the decentralized structure and vice versa. Is there a middle ground?
In a hybrid structure some aspects are centralized while the business units retain control over other elements. For example, data infrastructure, data strategy, hiring can be centralized, while the data professionals report into the individual business units, work on domain-specific problems by using the central data infrastructure (Figure 4.3).
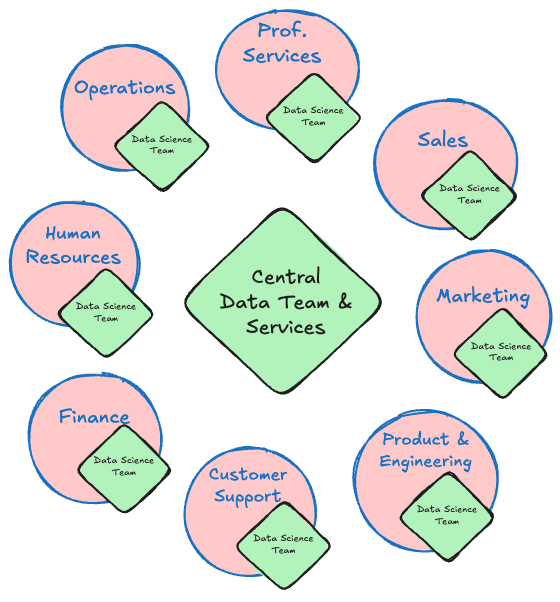
Key for the success of the hybrid strategy is that business (decentral) and data science management (central) need to be closely aligned. Otherwise the data teams get pulled apart between the direction of the central organization and the needs of the business units.