graph TD
A[Raw Data Sources] --> B[Data Engineering]
B --> C[Data Validation & Quality Checks]
C --> D[Feature Engineering Model]
D --> E[Data Preprocessing]
E --> F[Model Training/Retraining]
F --> G[Model Validation]
G --> H[Primary ML Model]
H --> I[Post-processing Model]
I --> J[Output Validation]
J --> K[Deployment to Production]
%% Resource Management
L[Resource Manager] --> B
L --> D
L --> F
L --> H
L --> I
%% Monitoring
M[Monitoring & Logging] --> B
M --> D
M --> F
M --> H
M --> I
M --> K
%% Feedback Loop
K --> N[Performance Metrics]
N --> O[Model Drift Detection]
O --> F
%% Styling
classDef dataNodes fill:#e1f5fe
classDef modelNodes fill:#f3e5f5
classDef systemNodes fill:#e8f5e8
classDef monitorNodes fill:#fff3e0
class A,B,C,E dataNodes
class D,F,G,H,I modelNodes
class K,L systemNodes
class M,N,O monitorNodes
45 Orchestration
45.1 Introduction
We know the difference between online and offline processing, have studied system architectures, and learned how to communicate between services using REST APIs. Now comes the part of ML Ops where it all needs to be stitched together: model orchestration.
Orchestration is where the components of ML OPs, namely machine learning, DevOps and data engineering come together into a workflow. Think of the orchestrator as the conductor of an ML orchestra, ensuring all the different models play their parts at the right time and in harmony.
Generative AI
This material was created with help of Claude 3.7 Sonnet from Anthropic.
45.2 Core Components
These are core components of model orchestration:
Workflow Management
involves defining the sequence and dependencies between different ML models. For example, you might have a feature engineering model that pre-processes data, followed by multiple prediction models that each handle different aspects of the problem, and finally an ensemble model that combines their outputs.
Resource Allocation and Scheduling
ensures models get the computational resources they need when they need them. This includes managing CPU, memory, and GPU allocation across different models, especially important when some models are computationally expensive while others are lightweight.
Data Flow Coordination
manages how data moves between models. This includes handling data transformations, ensuring consistent schemas, managing data lineage, and coordinating both batch and real-time data flows.
Model Versioning and Deployment
coordinates which versions of which models are running where. Different models might be on different release cycles, and the orchestrator needs to ensure compatibility and manage rolling updates without breaking the overall system.
45.3 Core Aspects
The core tasks of model orchestration fall into these categories:
Data Management
This includes data collection, pre-processing, feature engineering, and data versioning.
Model Training
Orchestration automates the process of training models, handling tasks like hyperparameter tuning and model selection.
Model Deployment
It manages the deployment of trained models to various environments, including setting up infrastructure and handling rollbacks if needed.
Monitoring
Orchestration tools monitor model performance in production, detecting performance degradation or anomalies and triggering retraining or alerts.
CI/CD and Testing
Integrates with CI/CD pipelines to automate testing and ensure model quality.
Scheduling
Automates the execution of tasks within the ML pipeline, such as training or data processing, on a scheduled basis.
System Health Tracking
It monitors the health and reliability of the infrastructure and components used in the ML pipeline.
Governance and Observability
Orchestration can also include features for managing access to models and data, as well as providing insights into the ML pipeline’s behavior.
45.4 Patterns
Pipeline Orchestration
arranges models in sequential workflows where the output of one model becomes the input to another. This is common in natural language processing where you might chain tokenization, embedding, and classification models (Figure 45.1).
Parallel Orchestration
runs multiple models simultaneously on the same input data. This is often used for ensemble methods or A/B testing scenarios where you want to compare different model approaches (Figure 45.2).
graph TD
A[Raw Data Sources] --> B[Data Engineering]
B --> C[Data Preprocessing]
C --> D[Feature Store]
%% Parallel Model Execution
D --> E[Model A Training]
D --> F[Model B Training]
D --> G[Model C Training]
E --> H[Model A Deployment]
F --> I[Model B Deployment]
G --> J[Model C Deployment]
%% Inference Phase
K[Inference Request] --> H
K --> I
K --> J
H --> L[Prediction A]
I --> M[Prediction B]
J --> N[Prediction C]
%% Ensemble/Aggregation
L --> O[Ensemble Model]
M --> O
N --> O
O --> P[Final Prediction]
%% Resource Management with Load Balancing
Q[Resource Manager & Load Balancer] --> E
Q --> F
Q --> G
Q --> H
Q --> I
Q --> J
%% Monitoring All Models
R[Distributed Monitoring] --> E
R --> F
R --> G
R --> H
R --> I
R --> J
R --> O
%% Model Comparison & A/B Testing
S[Model Performance Comparison] --> L
S --> M
S --> N
S --> T[A/B Testing Results]
T --> U[Model Selection/Weighting]
U --> O
%% Styling
classDef dataNodes fill:#e1f5fe
classDef modelNodes fill:#f3e5f5
classDef systemNodes fill:#e8f5e8
classDef monitorNodes fill:#fff3e0
classDef ensembleNodes fill:#fce4ec
class A,B,C,D,K dataNodes
class E,F,G,H,I,J modelNodes
class Q,P systemNodes
class R,S,T,U monitorNodes
class O ensembleNodes
Conditional Orchestration
uses business logic or model outputs to determine which models to invoke. For example, a routing model might first classify the type of input and then direct it to specialized models based on that classification (Figure 45.3).
graph TD
A[Raw Data Sources] --> B[Data Engineering]
B --> C[Data Preprocessing]
C --> D[Router/Classifier Model]
%% Decision Logic
D --> E{Input Classification}
%% Conditional Paths
E -->|Type A| F[Specialized Model A Training/Inference]
E -->|Type B| G[Specialized Model B Training/Inference]
E -->|Type C| H[Specialized Model C Training/Inference]
E -->|Unknown| I[Fallback/General Model]
%% Post-processing per type
F --> J[Type A Post-processing]
G --> K[Type B Post-processing]
H --> L[Type C Post-processing]
I --> M[General Post-processing]
%% Convergence
J --> N[Output Standardization]
K --> N
L --> N
M --> N
N --> O[Final Output]
%% Dynamic Resource Allocation
P[Dynamic Resource Manager] --> D
P --> F
P --> G
P --> H
P --> I
%% Condition-aware Monitoring
Q[Adaptive Monitoring] --> D
Q --> E
Q --> F
Q --> G
Q --> H
Q --> I
%% Feedback for Router Improvement
R[Router Performance Analytics] --> D
S[Model-specific Metrics] --> F
S --> G
S --> H
S --> I
R --> T[Router Retraining]
S --> U[Specialized Model Retraining]
T --> D
U --> F
U --> G
U --> H
%% Business Rules Engine
V[Business Rules Engine] --> E
W[Confidence Thresholds] --> E
%% Styling
classDef dataNodes fill:#e1f5fe
classDef modelNodes fill:#f3e5f5
classDef systemNodes fill:#e8f5e8
classDef monitorNodes fill:#fff3e0
classDef decisionNodes fill:#ffebee
classDef routerNodes fill:#e8eaf6
class A,B,C dataNodes
class F,G,H,I,J,K,L,M modelNodes
class P,N,O systemNodes
class Q,R,S,T,U monitorNodes
class E,V,W decisionNodes
class D routerNodes
Event-Driven Orchestration
triggers model execution based on external events like data arrival, threshold breaches, or user actions rather than following a predetermined schedule (Figure 45.4).
graph TD
%% Event Sources
A[Data Stream Events] --> B[Event Bus/Message Queue]
C[User Actions] --> B
D[System Alerts] --> B
E[Scheduled Triggers] --> B
F[Model Drift Alerts] --> B
%% Event Processing
B --> G[Event Processor & Router]
G --> H{Event Type Classification}
%% Event-Triggered Workflows
H -->|Data Arrival| I[Data Processing Pipeline]
H -->|Retrain Request| J[Model Training Pipeline]
H -->|Inference Request| K[Real-time Prediction Pipeline]
H -->|Alert Event| L[Incident Response Pipeline]
H -->|Batch Request| M[Batch Processing Pipeline]
%% Data Processing Branch
I --> N[Data Validation]
N --> O[Feature Engineering]
O --> P[Feature Store Update]
%% Training Branch
J --> Q[Data Preparation]
Q --> R[Model Training]
R --> S[Model Validation]
S --> T[Model Registry Update]
%% Inference Branch
K --> U[Model Loading]
U --> V[Prediction Generation]
V --> W[Response Delivery]
%% Incident Response Branch
L --> X[Alert Analysis]
X --> Y[Automated Remediation]
Y --> Z[Notification Service]
%% Batch Processing Branch
M --> AA[Resource Scaling]
AA --> BB[Batch Job Execution]
BB --> CC[Results Storage]
%% Resource Management
DD[Event-Driven Resource Manager] --> I
DD --> J
DD --> K
DD --> L
DD --> M
%% Monitoring & Feedback
EE[Event Monitoring & Analytics] --> B
EE --> G
EE --> H
%% Feedback Events
W --> FF[Performance Events]
CC --> FF
Z --> FF
FF --> B
%% State Management
GG[Event State Store] --> G
HH[Workflow State Manager] --> I
HH --> J
HH --> K
HH --> L
HH --> M
%% Styling
classDef eventNodes fill:#e3f2fd
classDef processingNodes fill:#f3e5f5
classDef systemNodes fill:#e8f5e8
classDef monitorNodes fill:#fff3e0
classDef responseNodes fill:#e0f2f1
classDef stateNodes fill:#fafafa
class A,C,D,E,F,B eventNodes
class I,J,K,L,M,N,O,Q,R,S,U,V,X,Y,AA,BB processingNodes
class DD,P,T,W,CC,Z systemNodes
class EE,FF monitorNodes
class G,H responseNodes
class GG,HH stateNodes
45.5 Implementation
Modern orchestration typically uses workflow engines like Apache Airflow, Kubeflow Pipelines, or cloud-native solutions like Databricks and AWS Step Functions. These tools provide visual workflow designers, dependency management, error handling, and monitoring capabilities.
The underlying infrastructure is often provided by container orchestration platforms such as Kubernetes (K8s). The container service provides service discovery, load balancing, and scaling capabilities for the individual model services.
45.6 Tools
There are many tools to choose from in the orchestration space, open-source and proprietary tools, and specialized ML platforms
The choice often depends on your specific needs: Airflow for complex, traditional workflows; Kubeflow for Kubernetes-native ML; cloud-native solutions like Databricks for tight cloud integration; and specialized tools like Metaflow or Flyte for ML-specific requirements. Many organizations use a combination—perhaps Airflow for data pipelines, Kubeflow for training orchestration, and cloud services for deployment.
The trend is toward more ML-aware orchestration tools that understand concepts like model versions, feature stores, and experiment tracking, rather than treating ML workflows as just another data pipeline.
Open Source Orchestration Tools
Apache Airflow is probably the most widely adopted workflow orchestrator in the ML space. Originally developed by Airbnb, it uses Python DAGs (Directed Acyclic Graphs) to define workflows. Airflow excels at complex dependency management and has extensive integrations with cloud services, databases, and ML frameworks. Its web UI provides excellent visibility into workflow execution and debugging capabilities.
Kubeflow Pipelines is specifically designed for ML workflows on Kubernetes. It provides a Python SDK for building pipelines and includes built-in support for experiment tracking, model versioning, and hyperparameter tuning. The visual pipeline editor makes it accessible to data scientists who prefer GUI-based workflow design.
Prefect positions itself as a more modern alternative to Airflow, with better error handling, dynamic workflows, and a more intuitive API. It has strong support for data science workflows and includes features like automatic retries, caching, and real-time monitoring.
MLflow focuses specifically on the ML lifecycle, providing experiment tracking, model packaging, and deployment capabilities. While not a full orchestrator like Airflow, it handles model versioning and deployment orchestration very well.
DVC (Data Version Control) brings Git-like version control to data and ML pipelines. It’s particularly strong for reproducible ML experiments and can work alongside other orchestrators for the version control layer.
Apache Beam provides a unified programming model for both batch and streaming data processing, making it excellent for data pipeline orchestration that feeds into ML systems.
Proprietary Enterprise/Commercial Tools
AWS offers several orchestration services: Step Functions for general workflow orchestration, SageMaker Pipelines specifically for ML workflows, and AWS Batch for large-scale compute orchestration. SageMaker Pipelines integrates tightly with other SageMaker services for end-to-end ML lifecycle management.
Google Cloud Platform provides Vertex AI Pipelines (based on Kubeflow), Cloud Composer (managed Airflow), and Dataflow (based on Apache Beam). Vertex AI Pipelines is particularly strong for AutoML and feature engineering workflows.
Microsoft Azure offers Azure Machine Learning Pipelines, Azure Data Factory for data orchestration, and Azure Synapse for big data workflows. The Azure ML Pipelines have good integration with Azure’s broader AI services.
Databricks provides a unified platform that combines data engineering, ML, and analytics orchestration. Their Jobs and Workflows features handle both data pipelines and ML model training/deployment. More on Databricks below.
Domino Data Lab provides an enterprise platform for data science with built-in workflow orchestration, collaboration tools, and model management.
DataRobot offers automated ML with built-in orchestration for model development, deployment, and monitoring.
H2O.ai provides Driverless AI and H2O Flow for automated ML pipeline orchestration.
Specialized ML Orchestration Platforms
Metaflow (originally from Netflix, now open source) focuses on data science workflow orchestration with strong support for versioning, scaling, and deployment. It bridges the gap between research and production effectively.
Flyte (from Lyft) is designed for production ML and data processing workflows, with strong type safety, versioning, and reproducibility features.
ZenML is an MLOps framework that provides abstractions for building portable ML pipelines that can run across different orchestrators and cloud platforms.
Databricks
Databricks is quickly becoming a standard in enterprise data science, machine learning, and artificial intelligence. If you work in organizations that deal with large data volumes, chances are you will encounter Databricks at some point.
Databricks is built on Apache Spark and combines data engineering, data science, and machine learning in a collaborative cloud environment. Founded by the creators of Apache Spark, Databricks is designed to handle the entire data science pipeline from raw data ingestion through model deployment. A large partnership with Microsoft Azure helped Databricks grow its business—but it is available across all three major cloud providers.
Architecture and capabilities
The core data architecture is built on the Lakehouse concept, the blend of data lakes and data warehouses introduced in Section 19.5. Lakehouse uses Delta Lake, Databricks’ open-source storage layer, and provides ACID transactions, schema enforcement, and governance on top of low-cost cloud storage like S3 or Azure Data Lake.
The core compute architecture is built around Spark clusters that scale automatically based on usage demand.
The ETL framework is declarative: you define what you want the data to look like and Databricks handles the implementation through their Delta Live Tables (DLT) framework.
The development environment is collaborative and based on the notebook paradigm, supporting multiple languages (Python, R, Scala, SQL) within the same notebook. Notebooks are integrated with git.
Databricks maintains MLflow as an open-source project and integrates it deeply into the platform to provide model registry, model deployment, and experimentation.
Feature Store centralizes feature engineering and serving for online and offline deployments.
Model Serving provides auto-scaling endpoints for online and offline serving, A/B testing, and monitoring for drift and performance.
Free Edition
Databricks provides a ton of capabilities in one platform; and it can be expensive. Pricing is based on the pay-as-you-go model where you pay for the resources you consume. It is often difficult to know a priori how much a particular job will cost. Is $5,000 per month a lot? It depends. It might be too expensive for a small startup. For a larger enterprise, getting data warehousing, analytics, and dashboarding done for $60K a year is inexpensive.
Thankfully, there is a (Databricks Free Edition](https://www.databricks.com/learn/free-edition) that provides complete access to their Data Intelligence Platform free of charge for students, hobbyists, and aspiring data and AI professionals—not for commercial use. There are some usage limits, for example, you are limited to a single SQL warehouse and up to 5 concurrent jobs per account.
The full UI is available; the free edition is a great place to try out some integrated ML orchestration, everything is available in one place.
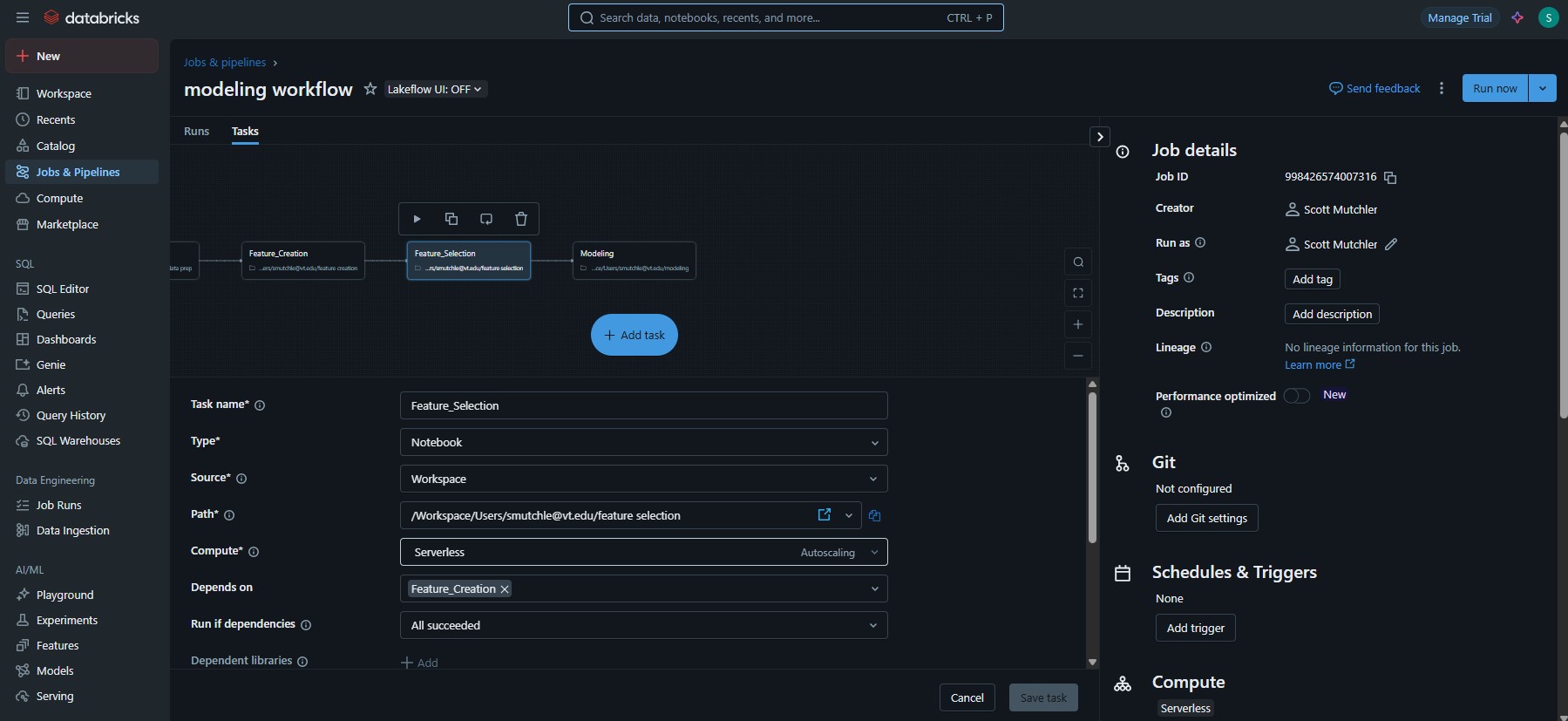
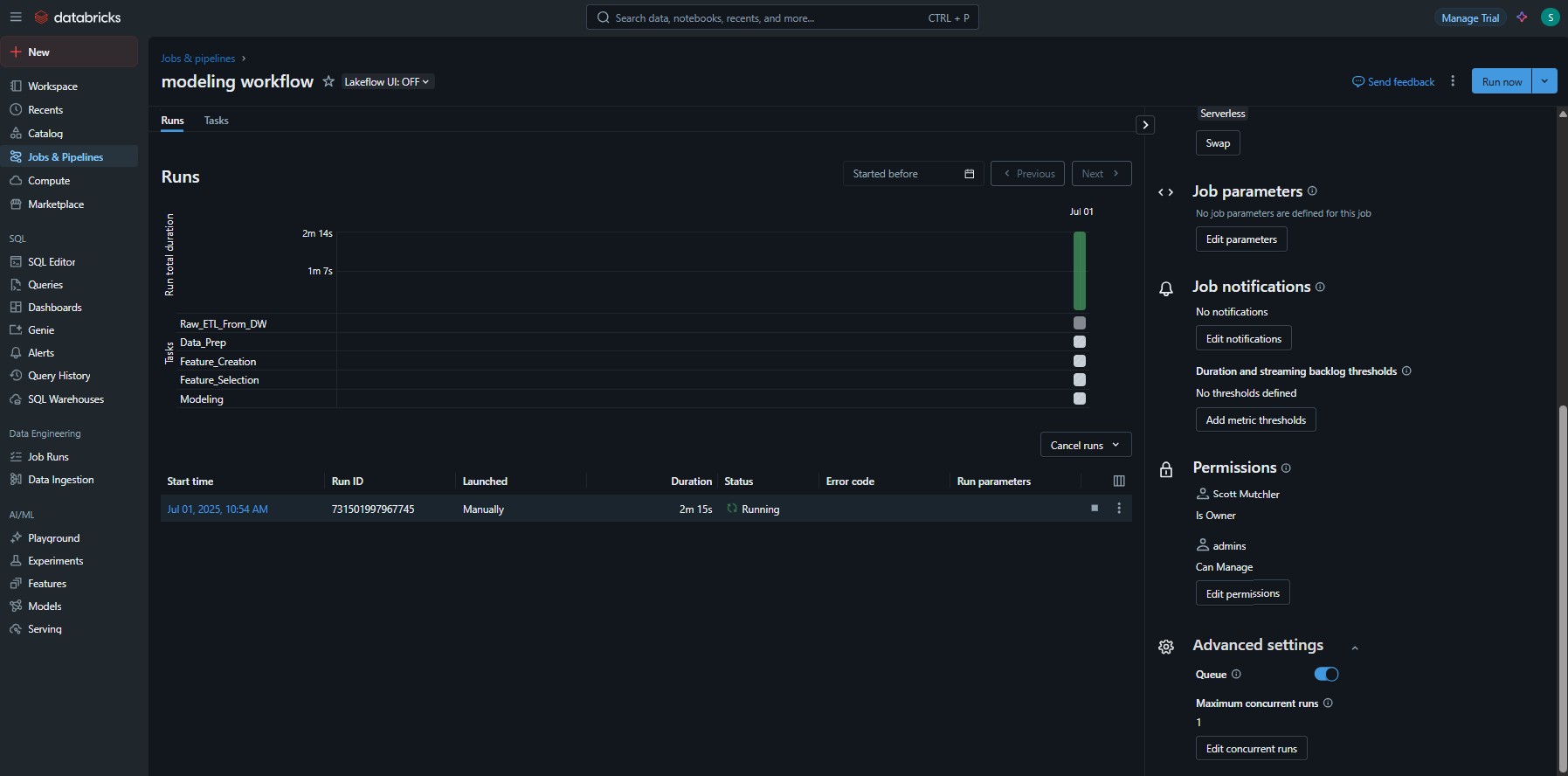
Screenshots
Figure 45.5 shows the general Databricks user interface and the setup of a modeling job that consists of ETL from a data warehouse, data preparation, feature creation, feature selection, and model training. Figure 45.6 shows the UI during the running of the job.