42 Offline and Online Operation
42.1 Introduction
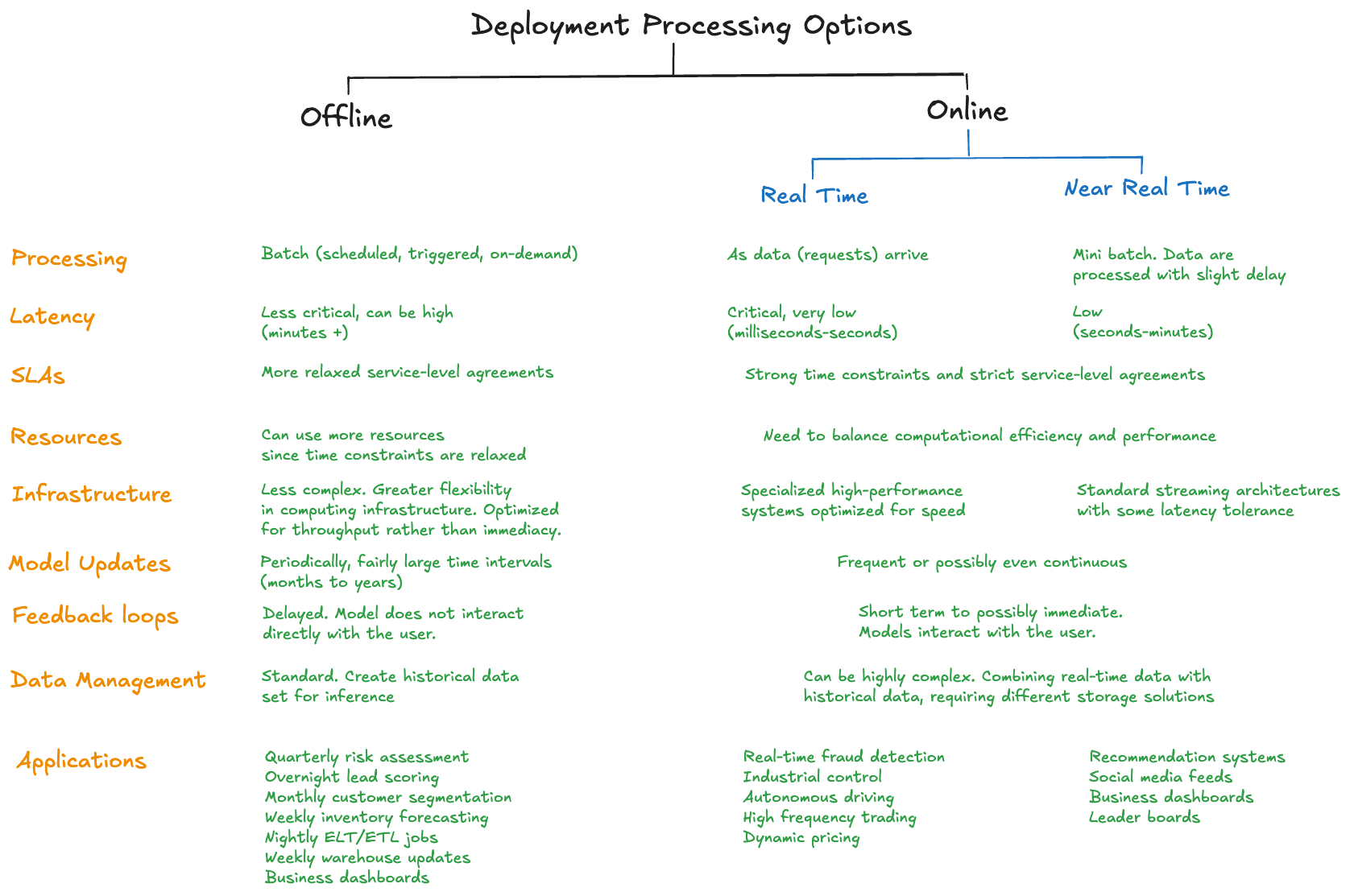
Let’s return to our lead scoring model. Suppose the model needs to be served in the following way. The scores have to be available to analysts in the sales operations and the marketing operations at the start of every business day. The analysts are familiar with SQL and will take the scores from a database to populate the dashboards in marketing and to feed the Salesforce instance for the sales team. The deployment of the new lead scores means to add the scores to the database(s) for the operations teams. It is not necessary to produce a lead score every time a new prospect is encountered. It is sufficient to collect the daily data for the new leads and compute the predicted scores on the set—this is called batch processing. The process described here is an example of offline processing (Figure 42.1).
Contrast this scenario with a recommendation system that must generate a recommendation as soon as the user interacts with the product or application. For example, a music recommendation is produced as soon as someone chooses to listen to a song—“you may also like…”. We cannot wait until the end of the day to produce a recommendation based on someone’s daily listening record. The real-time information on what song was chosen must be combined with previously collected behavioral information, the listener’s overall preferences, for example, to generate a recommendation in real time (as soon as the next song is chosen) or near-real time (by the end of the current song). This is an example of what we call online processing.
A data science model can be served offline in some applications and online in other situations. The recommender system that issues recommendations on demand when someone interacts with the system is served online. However, if the top 4 recommendations for each customer are to be included in a weekly e-mail from marketing to the customers, then it makes sense to pre-compute offline the recommendations for all customers and pull them into the e-mails as needed.
42.2 Offline Processing
Offline processing is also called batch processing because the model is applied to a batch of records at once. Offline processing is suitable for situations where instant results (low-latency responses) are not required and where throughput is more important than immediacy.
If you get a chance to deploy a data science solution offline, you should take it. Service-level agreements (SLAs) are the contracts between a service-level provider (you!) and a customer (the consumer of the model output). Consumers can be external customers or internal users such as an IT department, or the operations team of a business unit. In offline processing the end user of the model output does not directly interact with the model results, they are frequently stored and then processed before consumed by the end user. In the lead scoring example, the end users are the members of the sales team who use the lead scores to prioritize which potential customers to contact. The scores are served to them through the Salesforce application. The direct consumer of the model output is the operations team that pulls the daily scores from a database using SQL.
SLAs for offline processing are less strict. Whether the model scores the batch in 50 milliseconds or 30 minutes is irrelevant as long as the new scores are available when needed. This gives more flexibility in choosing the infrastructure for processing. Standard architectures work fine, whereas low-latency online systems require specialized streaming data engines, load balancing, and failover guarantees. Handling failures in offline systems by restarting the job is acceptable as long as the results are delivered within the SLA.
The data used in offline scoring is managed the same way as the training data. New records are formed based on the new info for scoring, merged with other attributes in the training data, and features are engineered on the combined data prior to scoring. Merging the new data with third-party data and historical data stored in other data platforms is part of the data engineering step of the scoring engine and can be performed prior to or as part of the batch processing.
Examples of offline applications are shown in Figure 42.1. They have in common that the delivery of the model results is periodic and asynchronous from the collection of new data. Note, however, that an application can be offline, real-time, or near real-time. A business dashboard, for example, can display information that was processed in batch, or can be updated in real time when new information becomes available. The correct approach depends on the application. A dashboard with sales revenue data for financial planning purposes can be updated once per day or once per week. Similarly for the billing dashboard shown in Figure 42.2. However, the chief sales officer wants to see updates in near-real time, within 30 minutes of deal closure.

An application monitoring devices on a network for cybersecurity breaches needs to respond within seconds of when an alert is issued (Figure 42.3).
42.3 Online Processing
Online applications process data as soon as they become available (real time) or after a small delay (near-real time). The path you choose depends on the latency requirements and your stomach for building complex high-performance systems. A credit card fraud-detection system might have a latency SLA of less than 50 milliseconds from receipt of the transaction data to issuance of a probability of fraud. Such SLAs ensure that there is no delay at the point of sale; the customer does not notice that a fraud probability calculation was part of the transaction. This is a real time system. Detecting medicare/medicaid fraud, on the other hand, requires lengthy investigations and network analysis that are performed offline.
Know Your Customer (KYC) applications in banking and fintech fall into the near-real time category. When you open an online banking account, documents are scanned and compared to databases to verify your identity and assess credit risk. Humans are in the loop to make decisions about edge cases. This happens within seconds or minutes from initiating the transaction. It could be done in an offline process where the bank processes a batch of account requests on demand (when a sufficient number of new requests have come in) or at fixed time intervals. While offline checks are done for deeper background checks or more detailed diligence for high-risk transactions, processing what can be done in near-real time creates a much better customer experience.
Real-time online systems are the most complex deployment option to implement. You should not go there unless the business case requires it. Over-engineering a solution with streaming data and low-latency response times is a mistake where that is not necessary. Online systems are not designed for throughput but for speed and resiliency. Retrying a failed job and doubling the response time might violate SLAs. Instead, active/active N+1 failover, where each system component has at least one independent backup component, and calculations are done by more than one unit, guarantee that you always have a result within SLA if a component fails—even if that means additional computations.
Exercises
Red Light Camera

A red light camera detects potential traffic violations in real time. Cameras take multiple pictures when they detect a vehicle moving after the light turns red and they are taking several seconds of video. While the data collection is in real time, discuss what systems would look like that determine violations and fines in
- real time
- near real time
- offline
You are the city manager installing red light cameras all over town. What deployment processing mode do you choose and why? Shame on you, by the way.
Airport Security
When you pass through airport security after checking in, the first stage is an identification check in front of a TSA officer. They check your ID (Real ID, driver’s licence, passport, …) and sometimes your boarding pass before your stuff is being scanned. Is this (should it be) a real-time or near-real time operation?
A particular challenge in online systems is the management of data. Models are trained offline on historical data sets that support batch processing of features. The same feature engineering steps can be difficult to perform when the model is served online. The data needed to score the model combines information gathered in real time and data from other sources. For model training, the analytic data set was processed ahead of time. At Uber Eats, for example, online estimation of the time to delivery combines information from the payload (the request) such as time of day and delivery location with historical variables such as average meal preparation time over the last seven days, and near-real time calculated features such as meal preparation for the last hour.
During scoring, the necessary pieces of information must be gathered on the fly unless they have been pre-processed and are available in a feature store. Calling out to other APIs, pulling records from offline databases, and so on, adds processing time and failure points.
Infrastructures for real-time online processing with complex data sources are thus highly complex systems. Their design and maintenance is beyond what a data scientist or a data science team can handle. Figure 42.4 is a schema of the online and offline prediction logic of Michelangelo—the in-house machine learning platform at Uber, discussed in this blog. The figure reflects the architecture in 2019, it has most likely not gotten any simpler since then. Offline feature stores in Hive and online feature stores in Cassandra work together to serve data for online processing. Because online processing cannot directly access the HDFS/Hive store, features for online processing are pre-computed and served through the highly available Cassandra database with low latency. All models are trained offline and made available to applications through a Cassandra model repository. Offline predictions use Spark, onine predictions have their own service.
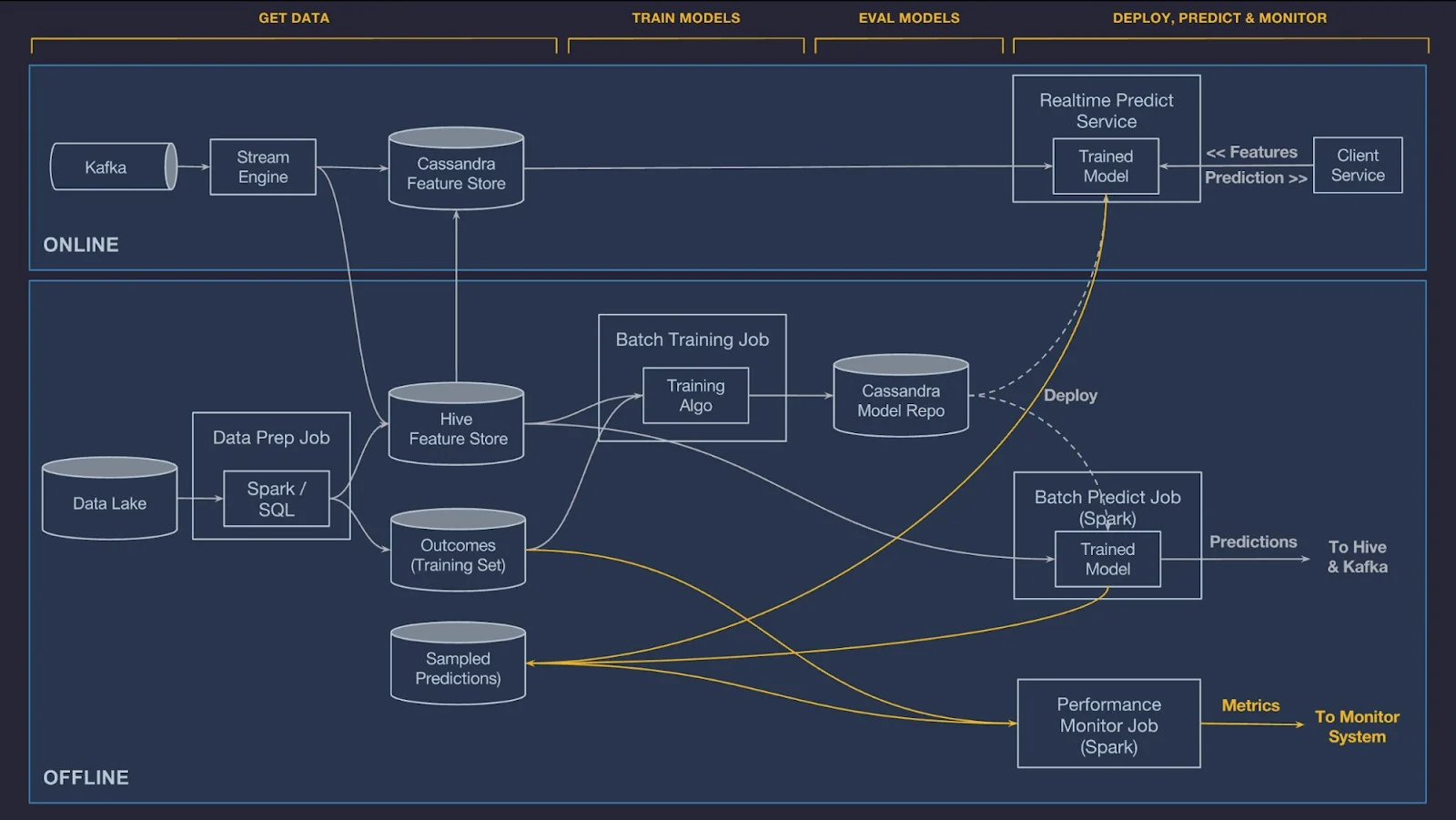
From the blog
The online part is primarily for making predictions with real-time and near real-time data that is collected via Kafka and pre-processed by streaming engines like Samza, Flink, etc. Eventually, they would be persisted in Cassandra feature stores. For the offline part, data collected from different sources would be pre-processed by SparkSQL and persisted in HIVE feature stores. Then we’ll train models based on the algorithms provided by the platform, which supports everything in Spark MLlib, some deep learning models, etc.