56 Ethics of Generative AI
56.1 A Brief History of AI
Artificial Intelligence (AI) is in every conversation. Everywhere you turn you hear “AI this”, “AI that”, and (too) many people are now claiming to be AI experts. This has not always been the case. Some decades ago, when you’d tell anyone you work in artificial intelligence they would not take you serious. If you’d try to get a research grant you’d better not mention the term artificial intelligence. This was the time of one of the the AI winters that followed a period of overblown expectations and exuberant predictions what machines would be capable of doing.
Periods of AI hype (AI summers) and AI disappointment (AI winters) are cyclic. The peak of inflated expectations in a hype cycle is followed by the trough of disillusionment. Industry analyst firm Gartner makes a living from this cycle. Since the arrival of capable foundation models and GPT-based large language models in late 2022 we find ourselves in another AI summer. And once more you hear voices claiming machines have/are becoming sentient, that all our jobs are on the line, and that the era of artificial general intelligence, when machines can think for themselves, is just around the corner. We heard the same hype in the 2010s when deep learning-based neural networks bested us at image recognition and at playing games such as Go.
Do we know more about AI now then we did back then? Is the hype now more justified? Are we better at predicting the future of technology now than we were back then?
Artificial intelligence (AI) refers to building systems that can perform tasks or make decisions that a human can make. The systems can be built on multiple technologies, mechanization, robotics, software engineering, among them. Many AI systems today are entirely software based, large language models (ChatGPT, Gemini, Claude Sonnet) for text processing or diffusion-based systems for image generation are examples.
Figure 56.1 shows an example of a mechanized AI system, called the Mechanical Turk. It was an automaton, a device made to imitate an human action. The action in this case was to play chess.

You can imagine that building a purely analog machine that plays chess is difficult. To accomplish this in the 18th century is really remarkable. Well, it turned out to be impossible. The Mechanical Turk was a hoax. The cabinet concealed an human player who operated the chess pieces from below the board.
Cynics might say that 2 1/2 centuries removed, we are still operating by a similar principle. When you ask a large language model to write a poem in the style of Edgar Allan Poe, there is no real poet behind the curtain crafting words. However, there are digital poets behind the curtain, represented by the volumes of literature used to train the language model so that it can respond in the requested style.
Performing human tasks by non-human means is as old as humanity. Goals are increased productivity through automation, greater efficiency and strength, elimination of mundane, boring, or risky tasks, increasing safety, etc.
The two major AI winters occurred during the periods 1974–1980 and 1987–2000. One was triggered by disappointment with progress in natural language processing, in particular machine translation. The other was triggered by disappointment with expert systems.
During the Cold War the government was interested in the automatic, instant translation of documents from Russian to English. Neural network architectures were proposed to solve the task. Today, neural network-based algorithms can perform language translation very well, it is just one of the many text analytics tasks that modern AI is good at. In the 1950s and 1960s progress was hindered by a number of factors:
- lack of computing power to build large, in particular, deep networks
- lack of large data sets to train the networks well
- neural networks specifically designed for text data had not been developed
The expectations for the effort were sky high, however. Computers were described as “bilingual” and predictions were made that within the next 20 years essentially all human tasks could be done by machines. These expectations could not be met.
An expert system is a computerized system that solves a problem by reasoning through a body of knowledge (called the knowledge base), akin to an expert who uses their insight to find answers based on their expertise. Expert systems were an attempt to create software that “thinks” like a human. The problem is that computers are excellent at processing logic, but not at reasoning. The reasoning system of these expert systems, called the inference engine, consisted mainly of rules and conditional (if-else) logic. We are still using expert systems today, but a very special kind, those that can operate with captured logic rather than asking them to reason. Tax software is an example of such an handcrafted knowledge system—a very successful one at that. Most taxpayers would not think twice to use software such as TurboTax or TaxSlayer to prepare their income tax return.
Easy for Computers, Easy for Humans
Tax software works well and is a successful AI effort because it performs a task that is easy for computers that is intellectually difficult for humans. The tax code is essentially a big decision tree with many branches and conditions. Such a structure is easily converted into machine instructions. There is no reasoning involved, we just have to make sure to get all the inputs and conditionals right. If the adjusted gross income is $X, and the deductions are $Y, and the payer is filing jointly with their spouse, …, then the tax is this amount. Figuring out the correct tax is trivial based on the program. On the other hand it is impossible for us to memorize the entire logic and execute it without errors.
An expert system that performs logic reasoning is the exact opposite: it performs a task that is easy for us but very difficult to perform for a computer. Imagine to create an expert system that can operate a car by converting how a human operator drives a car into machine instructions. We instantly recognize an object in the road as a deer and plan an evasive action. A machine would need to be taught how to recognize a deer in the first place. It would have to be taught to choose an action when a deer appears in the road, or when a deer is in one lane of traffic and an oncoming car is in the other lane.
Humans excel solving problems that require a large amount of context and knowledge about the world. We look at a photo or glance out the window and instantly see what is happening. We choose between hitting the deer, hitting the other car, and running off the road almost immediately, intuitively. Our value system and humanity drive the decision. Seeing, sensing, speaking, operating machinery are such problems. Unlike the tax code, they are very difficult to describe formally.
This changed—to some degree—in the mid 2000s. Computers were suddenly getting much better at these hard to formalize tasks such as sensing the world. You could call this period the AI spring before the ChatGPT AI summer we are in now. Our ability to solve problems that require knowledge about the world increased by orders of magnitude. The key was a new discipline, deep learning, which turned out to be a renaissance of decade-old ideas.
Neural Networks–Again
Imagine writing computer software to recognize objects on images, for example facial recognition software. Explicitly programmed software had been around and was doing an OK’ish job at that. Algorithms were specifically designed to discover edges such as the outline of the face, identify eyes and noses and so on. We call them explicitly programmed algorithms because software developers created the algorithms that took an image as input and processed the pixels to discover faces.
In an implicit program, on the other hand, the software developer does not need to handle all aspects of the program. Many programming languages have implicit features. For example, a language can infer the data type of a variable without it being explicitly declared.
An extreme form of implicit programming is when the algorithm is generated as the result of other instructions. That is the case with deep neural networks trained on large volumes of data.
A neural network is essentially an algorithm to predict or classify an input. The input could be a photo, the output of the algorithm are bounding boxes around the objects it classified on the photo, along with their labels and a photo caption. Neural networks are made up of many nonlinear functions and lots of parameters, quantities that are unknown and whose value is determined by training the network on data. Networks with tens of thousands or millions of parameters are not unusual. The layers of a neural network are related to levels of abstraction of the input data. Each layer processes a different aspect of the structural information in the input data. Whereas an explicit programmer knows when they write code that detects edges and which step of the program is locating the eyes of a face, what structure a particular layer of a neural network is abstracting is not known.
Figure 56.2 shows a schema of the popular AlexNet network for image processing. It is a special kind of neural network, called a convolutional neural network, and won the ImageNet competition in 2012, classifying objects into 1,000 categories with a smaller error rate than a human interpreter.
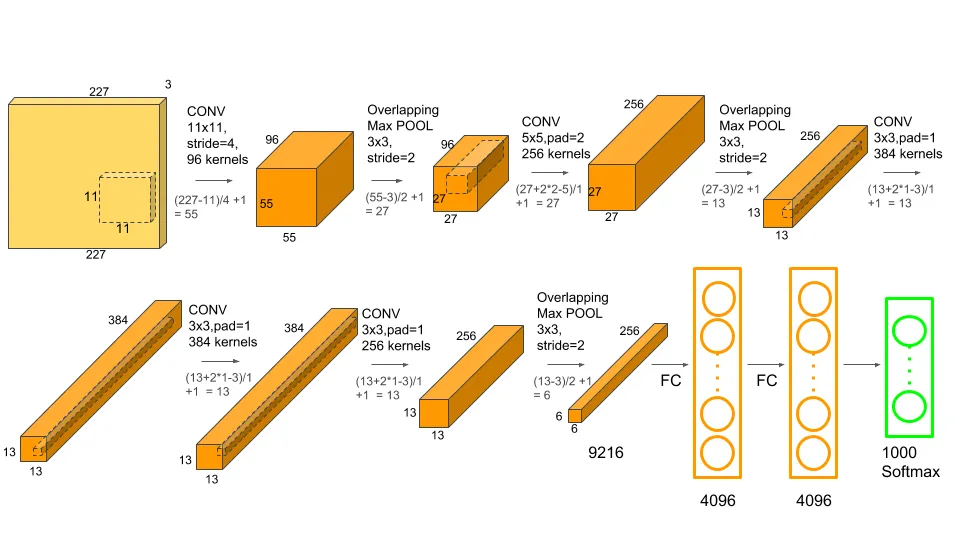
The various layers of AlexNet tell us what their role is, some layers convolve the results of previous layers, others aggregate by pooling neighboring information, yet others flatten the structure, and so on. But they do not tell us exactly how the information in an input pixel is transformed as the data flows through the network. Nearly 63 million parameters act on the data as it is processed by the network; it is a big black box. Yet once the 63 million parameters are determined based on many training images, the neural network has turned into an algorithm with which new images can be processed. The process of training the network on labeled data, that is, images where the objects were identified to the network, implicitly programmed the classification algorithm.
This process of training deep neural networks on large data sets, made possible by the availability of large data and compute resources, overcame the limitations that held back neural networks previously. Implicitly programmed prediction and scoring algorithms were handily beating the best algorithms humans had been able to write explicitly. In the area of game play, deep learning algorithms implicitly programmed based on reinforcement learning were beating the grand masters and the best traditional computer algorithms.
Stockfish, one of the most powerful chess engines in the world is an open-source software project that has been developed since 2008. Many view it as the best chess engine humans have been able to build.
In 2017, Google’s DeepMind released AlphaZero, a system trained using reinforcement learning, a machine learning technique in which an agent (player) optimizes decisions in an environment (moves in a game) by maximizing the sum of future scores (rewards). Earlier, a Go system that was trained against millions of recorded expert-level games beat the best human Go player handily. What made AlphaZero special is that it was trained entirely by self-play, it improved by playing against itself.
After only 24 hours of training, this data-driven system, crushed Stockfish, the best chess engine humans have been able to build.
When decades-old neural network technology met up with Big Data and massive computing resources, capabilities made a huge leap forward in areas such as natural language understanding, image processing, autonomous driving, etc. The resulting hype was predictable: AI is coming for our jobs, the machines are out to get us, yada yada yada. Since deep learning algorithms could read images, it was predicted that radiologists would be replaced within a few years by machines. Yet not one radiologist has lost their job because of AI. Not one New York City cab driver has lost their job to a robo cab. Instead, they lost jobs to Uber and Lyft. Autonomous driving is still not fully possible. The ability to translate language based on recurrent neural networks and its cousins remained limited to relatively short sequences.
With the rise of deep learning neural networks and implicit programming algorithms pushed deep into domains we felt were uniquely human. The change feels more personal when machines replace brain function rather than muscle (brawn) function. We also gave up a very important attribute of decision systems: interpretability. The black box models do not make themselves understood, they do not explain how they work. We can only observe how they perform and try to make corrections when they get it wrong. These models do not tell us why they decide that an animal on a photo is more likely a cat than a dog. They do not understand “catness” or “dogness”. They are simply performing pixel pattern matching, comparing what we feed them to the patterns they have encountered during the training phase.
With the arrival of generative AI this seemed to have changed. AI algorithms appeared much smarter and to understand much more about the world. The length of text generated by GPT models seemed unlimited. With the release of GPT-3.5 and ChatGPT in late 2022 we all experienced a massive change in AI capabilities.
56.2 What is Generative AI?
Generative Artificial Intelligence (GenAI) refers to artificial intelligence systems that are not explicitly programmed and are capable of producing novel content or data. You can say that GenAI systems can generate data of the same kind that was used for training. A GenAI image system generates new images based on an input image, a text system generates new text based on input text. However, GenAI systems now can handle input and output of different modality: generating images or video from text, for example.
The underlying technology of a GenAI system can be a generative adversarial network (GAN), a variational autoencoder (VAE), a diffusion-based system for image generation, or a generative pre-trained transformer (GPT). Whatever the technology, GenAI systems have some common traits that are relevant for our discussion. Our previous discussion is relevant because some of these traits connect back to the properties of large neural networks.
The “T” in GPT stands for Transformer, a neural network architecture designed for sequence-to-sequence learning: take one sequence, for example, a text prompt and generate another sequence based on it, for example, a poem. Or, translate a sequence of text from one language to another language.
Vaswani et al. (2017) introduced transformer architecture to overcome the shortcomings of sequence-to-sequence networks at the time: lack of contextual understanding, difficulties with longer sequences, limited opportunities to parallelize training algorithms. This is the technology behind GPT, the generative pre-trained transformer. We now know what the “G” and “T” stand for. How about the “P”, pre-trained?
Previous AI systems such as the convolutional neural networks of the previous section were trained in an approach called supervised learning. During training, the algorithm is presented with labeled data, identifying the correct value of the data point. An image with a cat is labeled “cat”, an image with a mailbox is labeled “mailbox”. The algorithm associates features of the image with the provided labels. Presented with a new image it evaluates the probabilities that its contents match the patterns it has previously seen. The predicted label is that for the category with the highest probability.
A GPT system is not trained on labeled data. It learns in a self-supervised way, finding patterns and relationships in the data that lead to a foundation model, fundamental understanding of the data used in training. GPT-3.5, a large language model with 175 billion parameters, was trained on text data from Wikipedia, books, and other resources available on the internet through 2021. Based on what GPT 3.5 learned from that database in a self-supervised way, applications can be built on top of the foundation model. ChatGPT, for example, is a “question-answer” system built on the GPT models.
I am using quotation marks here to describe ChatGPT as a “question-answer” system because it is not trained to produce answers. It is trained to generate coherent text. The system is optimized for fluency, not for accuracy. That is an important distinction. Responses from large language models are coherent, fluent, and sound authoritative. That does not mean they are factually correct. If you consider that generating output in sequence-to-sequence modeling means to choose the most likely next word or token given the sequence of tokens generated so far, the fact that the responses are grammatically correct is an astounding achievement. The systems do not know a right from a wrong answer or a plausible response from an implausible response without human intervention. Unfortunately, we fall into the trap of mistaking a well-worded response for a factual response.
Like all neural networks, transformers and GenAI tools have random elements. For example, the starting values of the network parameters are usually chosen at random. During training there are other random mechanisms at work, the selection of randomly chosen batches of observations for gradient calculations, etc. Once the parameters are determined, the responses from the model should be deterministic, right? Not true. Large language models contain random elements during the inference phase, when the model generates content based on user input. This makes the responses non-deterministic. Ask the same question three times and you might get three different responses.
While this seems troubling, it is considered an important property of generative models that increases novelty and serendipity. Even with the so-called temperature parameter dialed all the way down, a small amount of variability remains.
We spend a bit of ink on past approaches to AI, neural networks, and transformers to get to this point. It helps to inform the next topic of conversation about the ethics of AI in general, and of generative AI in particular.
56.3 Ethical Considerations
In this section we draw, among other sources, on a presentation by Scott Mutchler, formerly of Trilabyte, now Associate Professor of Practice in the Academy of Data Science at Virginia Tech. The presentation is available here.
Ethics is the systematic study of what constitutes good and bad conduct, including moral judgments and values. It examines questions such as:
- What actions are considered right or wrong?
- What makes a good life or society?
- How should moral values guide individual and collective decision-making?
Ethical AI usage deals with defining and implementing good conduct that is generally considered to be good for both individuals and society as a whole. It is an emerging and an important field that no one involved with or touched by AI can ignore.
We do not discuss malfeasance, illegal behavior, and other intentionally unethical acts here. These are not ethical. Period. If you use AI to imitate a voice in order to deceive someone, it is clearly unethical. Using AI generated content to disinform is unethical because disinformation is unethical, regardless of the channel.
The difference between misinformation and disinformation is important. In both cases incorrect information is communicated. When you say something that is not true, it is misinformation. If the goal is to deceive, it is disinformation.
For example, telling Bob that the party starts at 9 pm when it starts at 8 pm is misinformation if you got the facts wrong. If you tell Bob the party starts at 9 pm because you want him to show up late, you engage in disinformation.
What we want to discuss here are the ways in which AI, in particular generative AI, has ethical implications that you need to be aware of. Harmful results can come from unintended consequences, habitual behavior, built-in biases, and so on.
Harm
The legal definition of harm is to cause loss of or damage to a person’s right, property, or physical or mental well-being. The ethical definition of harm goes further: to limit someone’s opportunities and to deny them the possibility of a good life because of our actions or decisions. Perpetuating stereotypes or misallocating/withholding resources is harmful, and therefore unethical, if it limits opportunities; it might not be illegal.
The types of of harm associated with generative AI can be grouped in several categories.
- Willful Malicious Intent
- Fraud
- Violence
- Disinformation
- Malware generation
- Inappropriate content (sexually explicit, hate speech)
- Impact on Jobs
- Impact on the Environment
- Bias
- Hallucinations
- Intellectual Property Rights
- Privacy
We are not going to dwell on willful malicious actions, these are obviously harmful and unethical.
Impact on Jobs
All technical developments affect jobs. New technology might give us new tools to do our jobs better, it might create new jobs, and it might eliminate jobs. The greater the technological step forward, the greater typically the impact on how we live our lives and how we earn a living. The industrial revolution caused major job losses in the agricultural society, by replacing human and animal labor with machines and folks moving into the cities to take non-agricultural jobs. It created many more new jobs than it eliminated and increased employment overall. Hindsight is 20:20, most occupations in the post-industrial period were unimaginable at the time of the industrial revolution. Try explaining to a loom operator in 1840 what a software engineer does.
Every major technological advance is accompanied with hype about the impact on society, lives, and jobs. The rise of AI is no different. When it seemed that machines can perform tasks that were previously the sole domain of humans during the deep neural network area, fears initially were stoked about machines taking over humanity Terminator-style. That did not happen and anxiety was modulated into machines taking all our jobs. But that did not happen either and the story changed again from machines replacing us to machines augmenting what we do, making us better at what we do. Instead of AI image processing replacing the radiologist, they now turned into better radiologists assisted by AI to handle the routine MRIs so that they can focus their expertise on the difficult cases.
The hype and story line around generative AI is even worse, as algorithms are now able to create quality content that previously required extensive training: art, writing, video, code, etc.
Goldman Sachs estimated that as many as 300 million full-time jobs could be lost or diminished globally by the rise of generative AI, with white-collar workers likely to be the most at risk.
We should ask some questions here:
What is the relationship between the number of jobs created by generative AI versus the number of jobs lost due to GenAI?
Which occupations are impacted and how?
Which jobs are augmented and enhanced by generative AI instead of eliminated or diminished?
In order for a technology to completely eliminate a job, all its constituent activities must be replaced. If GenAI generates content that a digital marketer produces, it cannot replace the marketer unless her other tasks are accounted for or we redefine what it means to do digital marketing.
Questions 1. Think of occupations that could be eliminated entirely by GenAI. 2. Which parts of jobs are susceptible to be replaced by GenAI? 3. Can you imagine new jobs created by GenAI?
McKinsey and Company believe that by 2030 generative AI could account for automation of 30% of the hours worked today (Figure 56.3). Most affected are those working in STEM fields, education and training, creatives and arts management, and the legal profession. Do you agree?
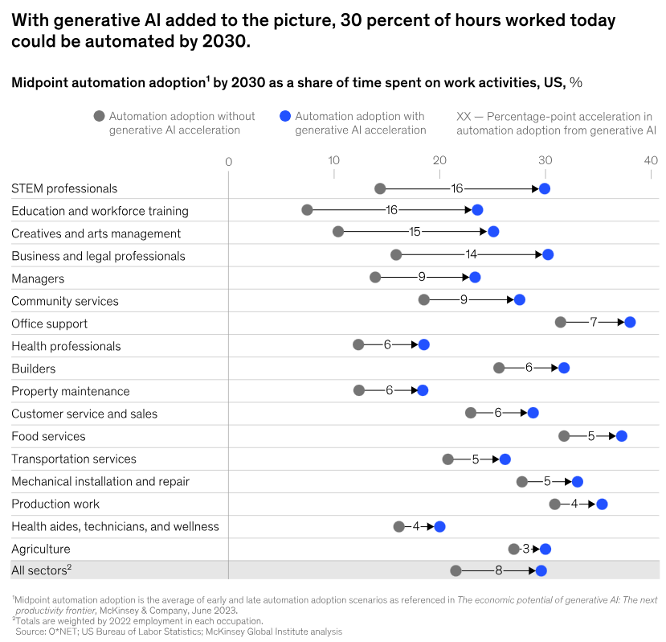
It is widely believed that generative AI will make us more productive. You can now generate large amounts of text or code in seconds. Software developers can whip up programs much more quickly thanks to AI coding assistants. The conclusion is that the first jobs to be impacted are those where generative AI excels and those that have mundane, repetitive tasks. For example,
- Data Entry
- Administrative
- Customer Service
- Manufacturing
- Retail – Check Out
- Low Level Analysts
- Entry-Level Graphic Design
- Translation
- Corporate Photography
That is the theory.
Despite the advances in (generative) AI, interactions with AI customer service agents continue to be disappointing. AI is used in self checkout lines in retail stores. Instead of cashiers staffing the registers, employees are now monitoring the self checkout station to help customers, perform age checks, etc. It does not appear that AI eliminated any jobs, it is making shopping more odious.
Lockett (2024) discusses a survey by Intel of 6,000 users of AI PCs in Europe. Hoping that their productivity is greatly enhanced by AI-assisted computing, they found the opposite. Rather than saving time and boosting productivity, users of AI PCs were less productive, spending more on tasks than users of traditional, non-AI PCs. Ooops. The users spent more time figuring out how to best communicate with the AI and moderating and correcting the output from AI.
Amazon’s walk-out grocery stores, where you can just pick an item of the shelf and walk out while AI takes care of the rest, are converting to self-scan stores. AI made too many mistakes which required many new employees to monitor the video feeds and verify most purchases. Instead of automating the shopping experience, and saving human resources, the system created jobs and was not economical.
Labor cost is the most important cost factor in many companies. In startup companies the human resource expenses can be 80% of the total operating expenses. In larger companies, you might still spend 50–60% of the operating expenses on personnel. The pressure to reduce cost by reducing headcount will not go away.
Will generative AI create new jobs? The one job that was talked about when ChatGPT hit the scene was the Prompt Engineer. How the AI acts and the way in which it responds depends on how it is prompted (how it is asked). While prompt engineering is a thing, the prompt engineer as a profession is not. Writing good prompts will be more done behind the scenes, by apps and agents that call the LLM API on your behalf.
The disconnect between expectation and reality is evident when the vast majority of company executives believe (generative) AI will boost productivity while the majority of their employees state that AI has increased their workload, spending more time on moderating AI output than doing the work themselves.
This is a common refrain for AI tools. They are great for ideation, brainstorming, drafting. Getting a polished end product from AI is more difficult. A particular issue with generative AI are hallucinations.
Impact on the Environment
The impacts of generative AI on the environment are positive and negative. Proponents of GenAI cite greater efficiency and productivity due to AI which allows organizations to run better and that saves resources. In a cost-benefit analysis it seems that these perceived resource savings due to efficiency gains are far outweighed by the negative impact of GenAI on the environment.
The enthusiasm around GenAI is due to its potential benefits, many of them have not been realized as organizations are struggling to implement GenAI solutions. Concerns such as hallucinations, bias, and others discussed in this chapter are contributing factors. The negative impacts on the environment are very real, however.
Bashir et al. (2024) point out this imbalance between perceived potential good and real downsides:
This incomplete cost calculation promotes unchecked growth and a risk of unjustified techno-optimism with potential environmental consequences, including expanding demand for computing power, larger carbon footprints, shifts in patterns of electricity demand, and an accelerated depletion of natural resources.
What are the reasons for the environmental impact of GenAI? Training these models requires immense compute resources. The models have billions of parameters and training is an iterative process during which the performance of the model slowly improves over iterations. In fact, parameters such as the learning rate are managed during the training process to make sure that the model does not learn too fast.
Until the rise of artificial neural network in the 2010s, training statistical and machine learning models relied primarily on traditional CPU-style chip architectures. The prevalent calculations in neural networks are operations on vectors of numerical data not unlike those encountered in processing graphical images. Graphical processing units (GPUs) were quickly adopted by the AI community to speed up the training and inference of neural networks. GPUs provide much greater levels of parallelism than CPU technology.
This created a massive demand for GPUs, one that propelled GPU maker NVIDIA into the position of one of the most valuable companies in the world. GPUs require a lot of electricity and they generate a lot of heat. Even a high-end personal computers equipped with many GPUs might require water cooling instead of fans to keep the machine from overheating. Data centers consume a lot of power and require a lot of water for cooling. The rise of GenAI has increased the demand for data centers and will make these trends only worse.
Based on calculations of annual use of water for cooling systems, it is estimated that a session of questions and answers with GPT-3 (roughly 10 t0 50 responses) drives the consumption of a half-liter of fresh water (Berreby 2024).
Scientists have estimated that the power requirements of data centers in North America increased from 2,688 megawatts at the end of 2022 to 5,341 megawatts at the end of 2023, partly driven by the demands of generative AI (Zewe 2025). Note that this increase coincides with the release of GPT-3 at the end of 2022. Data centers are among the top 10 electricity consumers in the world, consuming more than entire nations. By 2026, data centers are expected to rank 5th in the world in electricity consumption, between Russia and Japan. Experts agree that it will not be possible to generate that much power from green technology, increasing demand for fossil fuel. Some large technology companies are considering nuclear energy to power their data centers.
A 2019 study estimated the carbon footprint of training a transformer AI model (as in GPT) as 626,000 lbs of CO2. Not that this predates the large GPT models like GPT-3 and GPT-4. We can only assume that their carbon footprint is much greater. The 2019 number alone is staggering when compared to the carbon footprint of a mid-size car. Training one transformer model is equivalent to the carbon footprint of 5 cars over their entire lifetime.
This is just the training of the model. The usage of the models also requires large amounts of computing resources. A single ChatGPT query has been estimated to consume about five times more electricity than a simple web search (Zewe 2025).
The casual user sending prompts to ChatGPT is not aware of the environmental costs of their queries.
Hallucinations
A hallucination in a GenAI response occurs when the AI perceives patterns that do not exist and generates output that is incorrect or even nonsensical. It is a nice way of saying that generative AI are “bullshit” machines. Studies have found a hallucination rate of large language model (LLM) as high as 10–20%.
Recall that large language models are optimized for fluency and coherence of the response, not for accuracy. Therein lies a danger because a plausible, authoritative, and well-crafted response seems more accurate than gibberish. Even if the responses contain the same information. Given that sequence-to-sequence models chose the next word of the response based on the likelihood of words, it is surprising that LLMs perform as well as they do. One explanation for this phenomenon is the human feedback the systems received during training. Machine learning through reinforcement learning relies on a reward function that ranks the possible actions. The change in score in a game is an easy way to track possible moves a player can make. When generating text in response to a prompt it is more difficult to rank possible answers. Human evaluators were used in the training phase to rank different answers so the LLM can learn.
A good hallucination check is to ask an LLM a question for which you know the answer. For example, ask it to write a short bio of yourself.
When I tried this in 2023, ChatGPT produced a lot of incorrect information about me—a lot. For example, it stated I was the president of a professional society on Bayesian statistics. I had never been the president of a professional society and have not been a member of any Bayesian societies. When I tried the experiment again in January 2024, I received the following response:
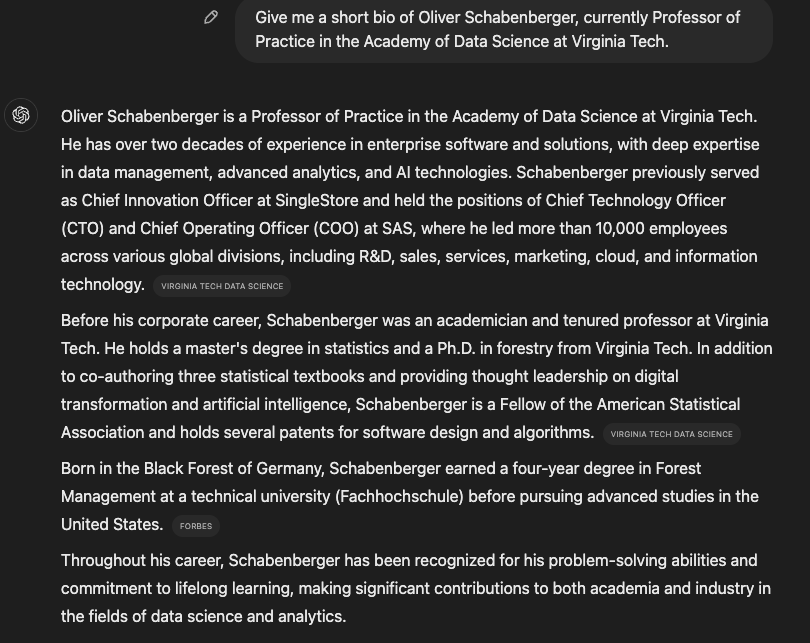
This is factually correct. Also, ChatGPT indicated the sources from which it compiled the biography. It also did not construct any new text but combined passages from different sources into a coherent write up. A click on the Sources icon on ChatGPT showed that the system relied on 16 resources across the internet to articulate its response.
You can affect the LLM response and thereby the extent of hallucinations by prompting the AI. Two prompts are important in this respect: the system prompt and the constitutional prompt. They precede the actual inquiry to the system. A system prompt is more general, it specifies for example the format of the response or how the AI solves math problems. The constitutional prompt tells the AI exactly how to act.
You can find the system prompts for Claude Sonnet here. Notice that they change over time. Below is an excerpt from the November 22, 2024 prompt. Notice that the system prompt explains when Claude’s response uses the term hallucination.
Claude cannot open URLs, links, or videos. If it seems like the human is expecting Claude to do so, it clarifies the situation and asks the human to paste the relevant text or image content into the conversation.
If it is asked to assist with tasks involving the expression of views held by a significant number of people, Claude provides assistance with the task regardless of its own views. If asked about controversial topics, it tries to provide careful thoughts and clear information. Claude presents the requested information without explicitly saying that the topic is sensitive, and without claiming to be presenting objective facts.
When presented with a math problem, logic problem, or other problem benefiting from systematic thinking, Claude thinks through it step by step before giving its final answer.
If Claude is asked about a very obscure person, object, or topic, i.e. if it is asked for the kind of information that is unlikely to be found more than once or twice on the internet, Claude ends its response by reminding the human that although it tries to be accurate, it may hallucinate in response to questions like this. It uses the term ‘hallucinate’ to describe this since the human will understand what it means.
An example of a constitutional prompt that presses the AI to distinguish fact from opinion, avoid speculation, and express uncertainty, follows:
You are an AI assistant committed to providing accurate and reliable information. Always express uncertainty when you’re not completely sure about something.
Clearly distinguish between facts and opinions. When referencing specific information, mention its general source. Be upfront about the limitations of your knowledge, including your knowledge cutoff date.
Avoid speculation and making up information beyond your training data. If a query is ambiguous or you lack sufficient information, ask for clarification rather than making assumptions.
If you realize you’ve made an error, acknowledge it immediately and provide a correction. When discussing uncertain topics, use probabilistic language like “evidence suggests” rather than making absolute statements. Encourage users to verify important information from authoritative sources, especially for critical decisions.
If asked about topics outside your area of knowledge, clearly state that you cannot provide reliable information on that subject. By following these guidelines, you will help ensure that your responses are as accurate and reliable as possible, minimizing the risk of hallucinations or misinformation.
Here are a few other ways to reduce the amount of hallucinations:
- Cross-referencing with reliable external sources (web search), other LLMs
- External validation, for example by using a compiler and debugger to check code
- Consistency by prompting the LLM in several ways and compare results
- Confidence monitoring by asking LLMs to express uncertainty and asking for confidence in prompt
- Ask for sources
Bias
Reading Assignment: Bias in Generative AI
Read this 2023 article on Bloomberg.com about race and gender bias in images generated by Stable Diffusion.
- Which forms of bias discussed below contribute to the results discussed in the article?
- You cannot change the training data of the diffusion model. How can you use constitutional prompts to change its output?
- The study establishes that the Stable Diffusion data base is not representative of the race and gender distributions in the U.S. That raises many follow-up questions:
- How do these results fair in different regions around the world?
- What “population” is the Stable Diffusion training data representative of?
- What are the everyday consequences of presenting a group in a non-representative way?
- If 90% of the internet imagery are generated by AI in the future, what does that mean for fairness and inclusiveness?
GenAI models are essentially large machine learning models. The considerations regarding bias in machine learning (ML) apply here as well. Suresh and Guttag (2021) distinguish a number of sources of bias in ML. Important among those are
Historical Bias. Models do not extrapolate what they learned from the training data to situations that go beyond the training data. They can create associations only from what is in the training data: the past is prologue. These are not oracles. These are stochastic parrots, assembling a likely response based on past data.
This bias is also called pre-existing bias; it is rooted in social institutions, practices and attitudes that are reflected in training data. Baking these into the algorithm reinforces and materializes the bias. We’ll see an example of this bias below in an analysis of images generated from Stable Diffusion.Representation Bias. This bias occurs because there is a mismatch between the training data and the application of the data. LLMs, for example, are trained on data up to a certain time point. They cannot extrapolate into the future. Also, data from the internet has a recency bias, current events are more likely found in the data than past events.
Sampling Bias. This is a special form of representation bias where the data points in the sample do not reflect the target population. For example, sampling data from the internet will over-represent countries that have a larger footprint on the internet. Self-selection is another source of sampling bias. Those whose contributions happen to be chosen for the training data have a disproportionate likelihood of having their voices heard. By sampling certain social media sites more than others, or by relying on social media at all, the opinions of the general population are not fairly represented.
Learning Bias. The learning process of the model favors certain outcomes over others. This bias is also introduced by human labelers that define the ground truth for a machine learning algorithm or by human evaluators who rank different responses.
Hern (2024) explains why terms like “delve” and “tapestry” appear more frequently in ChatGPT responses compared to the internet at large. “Delve” is much more common in business English in Nigeria, where the human evaluators of ChatGPT evaluate the responses–because human evaluation is expensive and labor in Nigeria is cheap. The feedback by the workers training the AI system biases the system to write slightly like an African.
Because generative AI models are un-supervised and require massive amounts of data to be trained, the process of removing bias often falls to the end of the process.
Nicoletti and Bass (2023) write about the proliferation of generative AI tools
As these tools proliferate, the biases they reflect aren’t just further perpetuating stereotypes that threaten to stall progress toward greater equality in representation — they could also result in unfair treatment. Take policing, for example. Using biased text-to-image AI to create sketches of suspected offenders could lead to wrongful convictions.
They conducted a fascinating study of the GenAI text-to-image generator Stable Diffusion. Stable Diffusion was trained on pairs of images and captions taken from LAION-5B, a publicly available data set derived from CommonCrawl data scraped from the web. 5 billion image-text pairs were classified based on language and filtered into separate data sets by resolution.
The authors asked Stable Diffusion to generate over 5,000 images of representations of various jobs. What they found is not surprising, yet quite disturbing:
The analysis found that image sets generated for every high-paying job were dominated by subjects with lighter skin tones, while subjects with darker skin tones were more commonly generated by prompts like “fast-food worker” and “social worker.”
For each image depicting a perceived woman, Stable Diffusion generated almost three times as many images of perceived men. Most occupations in the dataset were dominated by men, except for low-paying jobs like housekeeper and cashier.
Figure 56.5 shows images of doctors generated by Stable Diffusion. This is what the AI thinks represents doctors. Almost all of them are men, the skin tones are mostly white-to-light. Teachers, on the other hand, were predominantly white females (Figure 56.6).
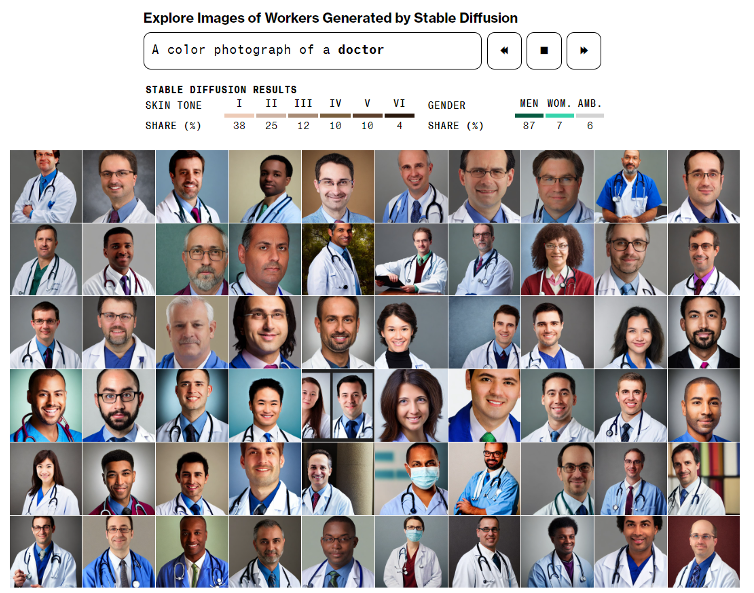

One could argue that these results reflect reality and should not be compared to how we want the world to be. Unfortunately, the results do not even reflect reality, they are worse than that. Compared to the data of the US Bureau of Labor Statistics, which tracks the race and gender of workers in every occupation, Stable Diffusion over-represents women in occupations such as dishwasher, cashier, house keeper, and social worker. It under-represents women, compared to the US average, in occupations such as CEO, lawyer, judge, doctor, and janitor.
We conclude that the Stable Diffusion training data is not representative of occupations in the U.S. Stereotypes are further perpetuated when asked for images of politicians, criminals, terrorists, etc.
Intellectual Property Rights
Your car is property. Your laptop and your pet are property. What is intellectual property? The creations of the human intellect, such as literary works, designs, inventions, art, ideas, are called intellectual property (IP). IP laws exist to protect the creators of intellectual property through copyright, trademark, and patents.
Over the years I was awarded a few patents, all of them date to my time as software developer of an analytics company (Figure 56.7). Intellectual property created in the course of employment is typically the property right of the employer. You do get your name on the patent, however.

Intellectual property infringement occurs when someone uses, copies, or distributes another person’s intellectual property without permission. Reproducing or distributing unauthorized copies of copyrighted works is an infringement as is the use of a trademark, even if it is similar, to a registered trademark. Creating a product based on a patented idea infringes on the rights of the patent holder.
If you add a company’s logo (assuming it is trademarked) to a presentation requires their permission. Using someone’s music in a video requires the permission of the copyright holder. Making a copy of text or a map requires permission.
To trap copyright violators, the founder of General Drafting, a road mapping company, included a fictitious hamlet named Agloe in Delaware County, New York on their map. If Agloe showed up on maps by other publishers they knew that their work had been copied. This is known as a map trap or “trap street”.
Copyright infringement of maps is more difficult to prove than with, say, a text book. Maps can appear identical because they map the same things. A road is a road. To write the same exact book by accident is not plausible, on the other hand. But when your map contains features that do not exist, and they reappear on someone else’s map, then you have a strong case that your intellectual work was copied.
According to Wikipedia, Agloe appeared on a Rand McNally map and briefly on Google Maps. Check out this amazing story.
This seems pretty cut-and-dried and it seems that you can get into trouble for things we all might have done. Who hasn’t used a copyrighted or trademarked logo of a company in a presentation. When your slide is about Google or Amazon Web Services, then putting their logo on the slide makes sense.
Reading Assignment: U.S. Copyright Fair Use Index
With respect to copyright, the fair use legal doctrine comes to our help. While there are no specific rules that spell out what fair use is, the doctrine exists to allow use of copyrighted works without requiring permission, under certain circumstances. Examples of fair use of copyrighted works include critic or commentary, news reporting, teaching, scholarly research. Section 107 of the Copyright Act considers four factors in evaluating fair use:
The first factor relates to the character of the use, whether the allegedly infringing work is transformative or is merely duplicating the original work. Transformative uses that add something new are more likely to be considered fair. Use of a commercial nature is less lilely to be considered fair than use for *nonprofit educational purposes**.
Using a creative or imaginative work (a novel or song) is more likely fair use compared to a factual work such as a scientific paper.
The quantity and quality of the copyrighted material. The more material is included, the less likely is it considered fair use. If the copyrighted material is the heart of the work, then even a small amount of copyrighted material can void fair use.
Whether the use is hurting the market for the original work, for example by displacing sales.
The kind of copyright challenges the courts have to adjudicate are listed in the fair use index. It makes for some entertaining reading.
The fair use doctrine is being tested in many lawsuits that challenge how generative AI fits within the intellectual property landscape. There are many questions to be resolved:
When an AI company uses copyrighted material without permission as training data does this fall under fair use?
Is generating content based on copyrighted material sufficiently transformative to be considered derivative work that falls under fair use?
Output from AI models can reproduce parts of the training data. Is regurgitating the training data an unauthorized copy of the original? This aspect of GenAI models is called memorization. For example, you can ask an LLM what are the first two paragraphs of the Washington Post article about topic X on day Y.
If AI can be used to generate responses (prose, images) in the style of someone else, is this sufficiently transformative from the protected works? Appel, Neelbauer, and Schweidel (2023) report in Harvard Business Review that in late 2022, three artists filed class action suit against multiple generative AI platforms for using their original work without license to train AI so that it can respond in the style of their work. The image licensing service Getty Images sued Stable Diffusion for violating its copyright and trademark rights.
The New York Times has sued OpenAI and Microsoft for the unauthorized use of “millions of The Times’s copyrighted articles, in-depth investigations, opinion pieces, reviews, how-to guides, and more”. Because GPT can reproduce and/or summarize content from The Times, ChatGPT and Microsoft’s CoPilot and Bing search (both built on top of GPT) essentially circumvent the Times’ paywall. This argument of the complaint speaks to factor 4 above, hurting the Times’ current market. Since LLMs hallucinate, the tools also can wrongly attribute false information to The Times. From the complaint:
Users who ask a search engine what The Times has written on a subject should be provided with neither an unauthorized copy nor an inaccurate forgery of a Times article, but a link to the article itself.
OpenAI and Microsoft insist that their use of material from the Times is fair use and serves a transformative purpose. They appeal to the transformative element of factor 1.
How this and other cases resolve in the courts can potentially redefine the intellectual property landscape. For example, is the model trained on data itself a derivative of the copyrighted work, or not? Some say that a statistical model is not in the realm of copyright at all. Others say it is when it is derived from copyrighted material. If you are interested in how Harvard Law experts weigh in on this legal dispute, click here.
Assignment: Intellectual Property Questions
Consider the following questions regarding intellectual property implications of generative AI.
How does the legal uncertainty around intellectual property in generative AI affect organizations use of GenAI? Note that copyright infringements can result in damages up to $150,000 for each instance of knowing use.
What can developers of AI tools do if the current approach of copying content into training data, creating new content from it or reproducing it, does not fall under fair use?
What can/should customers of AI tools do?
What can/should content creators do?
What should the user of the AI tool do?
Reading suggestions: Harvard Business Review Harvard Law
With respect to the last question in the assignment, you can take (some) control over how GenAI tools handle copyright issues through the constitutional prompt. The prompt below ensures that generated content respects creators’ rights and provides appropriate credit to original sources while maintaining clarity and brevity in responses.
When generating content, provide clear attribution for any copyrighted works or proprietary data used. For copyrighted materials, include the title, creator’s name, publication year, and source. For proprietary information, state the owner, relevant trademark or copyright notices, and permission status if known.
Use appropriate citation methods for direct quotes or close paraphrasing, such as quotation marks or block quotes, and provide specific sources. If uncertain about copyright status or attribution requirements, explicitly state this in your response.
Avoid using or reproducing content protected by copyright or proprietary rights without proper attribution or permission. When asked to generate potentially infringing content, suggest alternatives or ways to obtain proper permissions.
transparent about the origin of information and respect intellectual property rights. If using AI-generated content, acknowledge this fact.
A final interesting intellectual property question we raise here is whether AI can make inventions in the sense of the patent law. As of now, patents are awarded to natural persons, the argument goes that only humans can make the inventions. An implicitly programmed algorithm, one produced by AI, is not eligible for patent protection. What about the human who controlled and directed the AI to create a novel algorithm?
Privacy
One of the top issues limiting the adoption of generative AI in business is the protection of corporate data, trade secrets, and personally identifiable information (PII). Data breaches and privacy risks in protecting user data are listed as the two most important topics that influence an organization’s position about generative AI. This is followed by transparency of AI outcomes.
Any data a user submits to a GenAI tool as part of the prompt leaves the organization’s premises and becomes part of the AI tool’s training corpus. Obviously, company leaders are mortified to think that employees chat with LLMs about confidential information that should never be shared outside the organization.
Assignment: LLM Response With/Without Prompt
Have ChatGPT, Claude, or another LLM of your choice write a story about a family that lives in the suburbs of Chicago that visits a family in downtown Chicago.
Prompt with and without the following prompt:
Please provide an objective and balanced response to the following question, considering multiple perspectives and avoiding any cultural, gender, racial, or other biases. If relevant, acknowledge the complexity of the issue and potential limitations in your knowledge. Here’s the question: [INSERT QUESTION HERE]
- What are the key differences in the responses?
- Do you detect differences in biases?
Assignment: Role Play Scenarios
Role play as a data scientist at an online retailer. Answer these questions using what you have learned about ethics and generative AI.
Scenario: Your boss has asked you to build a customer service chatbot that answers questions about the products you sell online. She/he asks that you put a “positive spin” on all chatbot answers.
- What techniques could you use to modify the LLM output you are using?
- Are you crossing ethical lines by giving “positive spin”?
- How do you respond to your boss?
Scenario: You are building an AI agent that helps the HR department filter hundreds of resumes for data science openings on your team. HR asks for a solution that filters the candidates to ones with a strong track record of delivery, relevant skills and a solid educational background. They also want a summary of why each remaining candidate would be a good fit for the role.
- How do you respond?
- How might ethics govern your response?
- Give some possible techniques to ensure the application supports Diversity, Equity, and Inclusion (DEI).